Augmented Reality Databases
Recent breakthroughs in spatial computing, real-time navigation, and computer vision have turned augmented reality from some pretty cool science experiments into a booming business, rolled out in all sorts of places, from building sites and factories to city planning and real estate firms.
When you take a step back and think about AR as a system, though, it becomes clear that it is very data-intensive and latency sensitive – you need to be able to grab, sort, and display digital info on the fly, all while making sure it matches up with the real world. That puts serious pressure on how we store, track, and serve that data.
Augmented reality database systems are collections of storage solutions and databases that enable all the above. What makes AR databases so challenging is that augmented reality apps don’t usually rely on a single database. Instead, they tend to mix and match different database systems – spatial ones, relational ones, semantic ones, and even object storage systems – each tailored to the type of data and its access requirements.
This article will cover augmented reality databases in depth, including data requirements for AR applications, the main database categories used in AR systems, and provide best practices based on real-world patterns.
Summary of key augmented reality database concepts
The table below summarizes five augmented reality database concepts that this article will explore in more detail.
| Concept | Description |
|---|---|
| Augmented reality databases | AR needs a place to store all that spatial, temporal, and digital data. Most of the time, AR apps aren’t just using one database; it’s either one alone or a combination of a few working together to store spatial data, object data, and digital content. We’ll call these AR databases. |
| Cloud-based AR services | There are AR services that run entirely in the cloud – Google’s ARCore Geospatial API and Apple’s ARKit location anchors are two examples. |
| Deployable AR Databases | Databases like PostgreSQL, SQL Server, and Oracle have AR data covered – they offer special plugins or versions that make storing AR data easy. Some popular examples are PostGIS, MongoDB with its geospatial indexes, and Oracle Spatial. |
| Graph Databases | Graph databases, like Neo4J, are pretty valuable in AR because they make it easy to represent that semantic AR data and how objects are related to the places they are in. |
| Object storage | AR applications accumulate heaps of digital content – think images, video, and audio. For storing all this media, you need object storage systems like AWS S3, Google Cloud Storage, or IPFS. |
Understanding augmented reality applications
AR applications are a practical example of what can be broadly defined as spatial computing. They combine real-world sensing, spatial models, and digital content to deliver contextually oriented information in a manner consistent with the physical environment. Unlike just sticking a map on your screen, AR systems have to keep track of where you are, which direction you’re headed, & what’s around you – all in real time.
AR is getting used in all sorts of places now. In construction & engineering, they use it to show BIM models on-site & do a ‘before & after’ on the plans versus what actually got built as a result. In manufacturing, AR helps people assemble components, inspect for quality & do maintenance tasks. In infrastructure & asset management, AR lets people view underground utilities, view inspection records, or sensor data, all in context. Realtors, hospitality & urban planners are even using AR to create these immersive experiences & tell a more comprehensive story about a place.
From a data architecture perspective, AR is as complex as it can get. It’s got to work with really low latency, even on smartphones and smartwatches, while keeping track of where things are in space and making them relevant to what the user’s looking at. All those demands have a direct impact on how data gets stored, structured & delivered.
AR systems use many different kinds of data, each with its own quirks and requiring special handling. Trying to put all that data into a single bucket will cause performance or integration issues.
Relational Data
The neatly structured kind of relational data is the kind that has unique IDs, what it is, where it is in the lifecycle, who owns it, and all that stuff. Such info is typically in relational databases you use to filter, search, and join data.
For example, a simple relational table for AR-visible assets might look like:
CREATE TABLE city_assets (
asset_id SERIAL PRIMARY KEY,
asset_type TEXT,
status TEXT,
last_inspection DATE,
spatial_ref_id INTEGER
);Relational data by itself gives no sense of where things are in space, but it makes tracking things easy, even across systems. You connect those spatial features with some meaning and actual content in AR workflows using relational tables.
Spatial Data
Spatial data tells us where digital content fits into the real world – or rather, where it is in the physical space. This includes everything from single locations to many different lines, shapes, and 3D models, the framework that ties them all to real-world locations, and systems that help us quickly find where the data is. In augmented reality applications, getting the location right is important. A tiny misalignment between a digital overlay and the real world can make the whole thing look and feel completely disconnected.
It’s often stored in a database extension like PostGIS or Oracle Spatial or in a spatial-aware system like ESRI’s ArcGIS. For example, someone’s point of interest database might look like this:
CREATE TABLE poi
(id SERIAL PRIMARY KEY,
name TEXT,
geom GEOMETRY(Point, 4326)
);You need to efficiently find specific data and handle the fact that this data is distributed across different locations. That becomes important especially when you’re combining data from various sources. Or maybe your AR system runs in different parts of the world, where different location systems are used.
Temporal Data
Lots of AR use cases involve data that changes over time. We’re talking about all the stuff that shifts over time, like what phase a construction project is in, where maintenance has been done and when, when inspections were done, and what sensors have observed. All the time-dependent info lets AR applications show users the relevant stuff at a certain moment – rather than just a snapshot that’s stuck in time.
For instance, an AR application could let users see what an asset looked like on a specific date and even let them replay how it changed over time. Most of the time, this sort of data gets stored along with other data like relationship records or spatial maps – but handling it all carefully is a must to avoid getting it all mixed up.
Digital Content
AR applications usually point to all sorts of digital content like images, videos, audio clips, and 3D models that are not easily handled like plain old tabular data. These assets tend to be large and are usually accessed differently from regular data – plus they are updated on their own schedule, unlike regular spatial or relational data.
The idea of storing all that extra data in relational or spatial databases is pretty impractical. Instead, AR systems usually just store a pointer to where the data is actually located, like a URL pointing to an object storage service.
{
"asset_id": 1023,
"thumbnail_url": "https://storage.example.com/assets/1023/preview.jpg",
"model_url": "https://storage.example.com/assets/1023/model.glb"
}Each of these data types has different storage needs. To start off, spatial queries need some form of spatial indexing; media delivery works better with content-optimized storage; and when it comes to semantic relationships, well, a graph model just naturally fits the bill. Trying to make a single database handle all of these needs pretty much guarantees you will end up making some compromises somewhere, and that’s usually on scalability or flexibility.
As a result, nearly every AR system ends up leaning on a mix of databases and storage services. So, when we talk about an AR database, let’s not think of it as a specific product, but rather as a capability that any AR architecture should deliver, storing and serving what AR applications need, that kind of thing.
Traditional spatial databases are all about storing and querying geographic features, which is a foundational block for AR systems, but they don’t go the whole distance for what AR needs. AR-ready database architectures, on the other hand, not only cover spatial storage but also store links to digital assets, identify semantic connections between objects, incorporate temporal context, and account for real-time rendering and mobile hardware.
Types of augmented reality databases
At a high level, AR databases can be grouped into three categories: spatial data storage, semantic data storage, and object storage and analysis. In this section, we’ll take a closer look at each of these types of augmented reality databases.
Databases for storing spatial data
There are several different approaches teams can use for storing spatial data for AR use cases. Let’s take a look at the two most common.
Cloud-based AR services
Some spatial computing platforms offer fully managed, cloud-based AR services that sort out the tricky business of localization and anchoring for you. Think Google’s ARCore Geospatial API and Apple’s ARKit location anchors – these are just a couple of examples of services that can take away all the fuss of getting digital content to line up with the real world.
Interestingly, though these platforms make certain aspects of developing AR much easier, they’re often pretty limited when it comes to data schemas, long-term storage, or integration with existing corporate data systems. As a result, they’re often used in conjunction with a self-managed database rather than as a complete data solution, due to their limitations.
Traditional databases with spatial extensions
Many AR systems rely on established database platforms that have been supercharged with spatial capabilities. Look at some examples:
- MongoDB with geospatial indexes (because who doesn’t love a bit of spatial searching)
- PostgreSQL with PostGIS (a really popular choice)
- Oracle Spatial (for a more traditional RDBMS setup)
These systems allow you to store spatial data right alongside all your relational attributes, and you can even get all that data to play nice with your wider data ecosystem. Additionally, they support all the spatial querying, indexing, and transformation you need to get your AR app up and running.
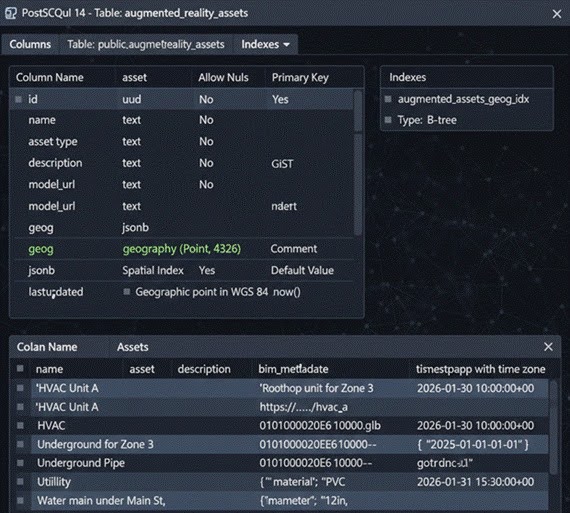
Databases for storing semantic data
Graph databases are the most common type of database used for semantic data. When building AR applications, you often need to show relationships between all sorts of things – objects, places, concepts. And that’s where graph databases come in. They are perfect for laying out these relationships in a clear, easy-to-understand way.
For example, a graph model might represent relationships like:
(Building) - [:CONTAINS] -> (Floor) - [:CONTAINS] -> (Room)
(Room) - [:HAS_ASSET] -> (Equipment)This approach lets AR applications get the information they need super fast, like listing every asset in a room or every room in a building. No need for all the complicated joins that other database systems would require.
Systems for object storage
When you’ve got big digital assets to store, you want them in a system that’s built to last, can scale up when you need it to, and can get the files you need quickly. That’s what object storage is all about, and it’s what systems like AWS S3, Google Cloud Storage, and even decentralized solutions like IPFS are made for.
In an AR application, object storage is usually tied to spatial or relational records by an identifier, rather than embedded in them. And that makes sense because it lets you scale up your media or manage its lifecycle on its own terms.
Data processing for AR applications
One of the most practical challenges in AR systems is coordinating data updates across spatial databases, semantic stores, and object storage, to name a few. You need to make sure that any changes you make are reflected in all of them, which can be a real challenge when you have to write scripts to do it. And even then, when things don’t go according to plan, those scripts can be difficult to maintain.
Atomic updates across all these systems may not be straightforward.
Data integration tools help by giving you a way to set up a system that can handle all this data shuffling in a predictable way, transform the data, verify its quality, and load it into the various places it needs to go. This way, you can keep all the data prep work separate from your application code.
A tool like FME is often used to prepare your data for AR use by transforming GIS, BIM, and asset data, aligning coordinates, adding metadata, and then spitting out results in a format AR clients can use.
Workflow example: preparing data for an AR application
To demonstrate how AR-ready datasets are prepared in practice, a small example is shown here. For the entire workflow, FME was used to prepare and process spatial data for direct consumption by AR clients and structured databases.
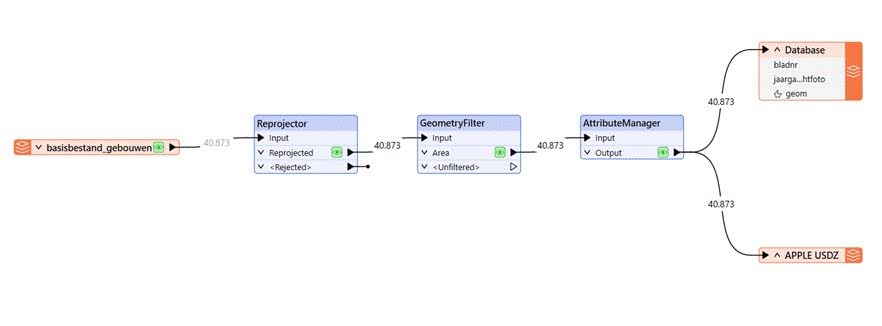
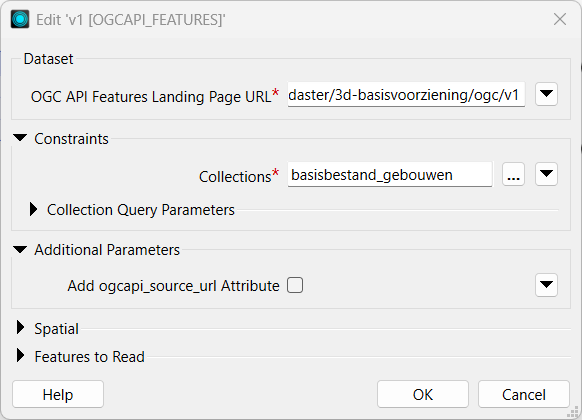
- The workflow begins with an OGC API Features Reader, which allows you to provide an API / URL as input, choose a data collection, and then extract the data for you. This reader fulfills the “Extract” step in this ETL pipeline and targets the 3D Buildings data for the Netherlands from the “basisbestand_gebouwen (basic_buildings)” collection. Reading live data like this ensures the model will always be working with the most recent 3D data rather than static or outdated files.
- Standard GIS data from a public map services portal like PDOK (Publieke Dienstverlening Op de Kaart, in Dutch) usually uses local coordinate systems (such as the Dutch RD New, in this case). However, for global positioning and scalability of your project, it is best to use a global standard 3D coordinate system, such as WGS84 (lat/long). The Reprojector transformer in FME handles this step. This transformer can project your datasets to the desired Coordinate Reference System.
- A GeometryFilter transformer was then used to isolate “area” or polygon geometries (e.g., building footprints) and remove unexpected geometry types (e.g., points, lines, point clouds). Any invalid or problematic geometries are identified early at this stage, before they propagate to the downstream workflow.
- A “database” can contain lots of information; however, sending 50 columns of unrequired data to an AR is too much. The AttributeManager transformer was used to keep only the important fields: the building IDs and the year when the aerial photographs were taken (jaargang_luchtfoto).
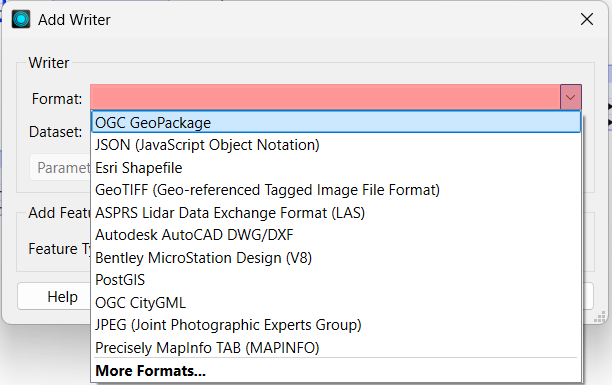
- FME allows you to extract the output of your analysis in multiple formats. For our workflow, the prepared dataset was then written to a PostGIS table with spatial indexing enabled (GiST) and used for proximity queries such as “find buildings near XYZ location.” Additionally, a Universal Scene Description Zip (USDZ) writer exports the data in a format needed for AR rendering workspaces. USDZ format is also widely supported for native 3D rendering in the Apple AR ecosystem on iOS.
In this workflow, PostGIS stores authoritative spatial data used for contextual filtering or querying, while the USDZ files can serve as the visualization output delivered to an AR client. Both outputs were easily generated within a single automated data pipeline, done using a no-code platform like FME. The model was quick to build (only a few button clicks), and because of its direct connectivity to the live data source, it can be rerun whenever updates are required without rebuilding the entire workflow.
Best practices for working with augmented reality databases
Organizations that get the most out of their augmented reality database systems are those that understand the tradeoffs and make pragmatic decisions in context. Unfortunately, what works for one team might not work for another. Fortunately, there are several proven best practices that can help you get it right.
Design for spatial data first
You have to define coordinate reference systems, spatial resolution, and geometry types early in the design process. Ensure that all datasets have appropriate, matching coordinate reference systems and that their metadata are consistent (resolution, acquisition time, units, etc.). One of the most important steps in any spatial analysis is to confirm the CRS of all the involved datasets and reproject them to a common system before running any analysis. Early validation of metadata also prevents semantic misinterpretations that may occur further down the pipeline. Spatial inconsistencies introduced at this stage are difficult to correct and directly affect AR alignment accuracy.
Separate metadata from asset-heavy data
Store your structured metadata in a relational or spatial database, and use object storage for your large digital assets. Then use stable IDs to link the two parts instead of embedding the asset directly in the database record.
Account for latency constraints
AR is super sensitive to even the slightest delays in data access and rendering. So make sure you’re optimizing your data payload size, query performance, and network interactions to work around that.
Use databases based on data characteristics
See if some assets can be generated as needed using techniques such as procedural methods or AI tools, rather than storing them permanently on a hard drive. This can save some space, but you do have to figure out how to balance that out with what it takes to get the job done quickly and reliably.
Generate assets dynamically when appropriate
See if some assets can be generated as needed using techniques such as procedural methods or AI tools, rather than storing them permanently on a hard drive. This can save some space, but you do have to figure out how to balance that out with what it takes to get the job done quickly and reliably.
Automate data preparation workflows
One of the best practices for augmented reality databases is automating workflows to ensure consistency, reproducibility, scalability, and, most importantly, to minimize human error. FME helps you eliminate hundreds of lines of code and potential bugs by separating a workflow’s phases into distinct visual transformers. FME can perform the same tasks as a complex Python workflow in minutes, without the need for environment setup or dependency management. Logging, debugging, schema mapping, QA checks, and reruns are also included, which help stabilize the workflow in production. FME dramatically simplifies workflows, making it the best choice for AR databases.
Validate datasets on small subsets
Test AR datasets using limited, representative subsets before scaling to full coverage. For large amounts of geodata, run the workflow on a small test dataset initially to identify troublesome areas. Try the workflow on the subset and adjust as necessary. Running the analysis on a small area of interest can help identify invalid geometries, CRS mismatches, and other inconsistencies, which is very helpful in the long run. After the workflow is confirmed and finalized, apply it to the remaining data using batch processing tools such as FME. This practice helps identify spatial misalignment, performance issues, and modeling errors early.
Monitor data preparation processes
Log and monitor how your data-prep workflows are performing, including validation outputs, errors, and all the transformation steps performed. Logging allows fast traceability, debugging, and auditing/rollback. FME logging is automatic and very easy to read in the software’s interface. Each transformer in FME reports warnings, data counts, and process failures. Good logging should catch mismatches in CRS, failed API requests, or invalid geometry before they produce incorrect outputs. If something goes wrong or data starts to get wonky, you can catch it before it causes too much trouble.
Conclusion
Augmented reality database systems have stringent requirements. Data must be accurate, delivered in real time, and consistent. This usually involves bringing together several database technologies rather than relying on a single system to handle everything. One can think of AR databases as coordinated architectures that combine spatial databases, semantic models, object storage, and automated Extract-Transform-Load pipelines to build a unified AR system. Building an AR system through FME is scalable through prototypes and maintainable over time. Well-created workflows are the foundations of production-grade AR systems.
Continue reading this series
Spatial Computing
Learn the basics of spatial computing and its benefits, key applications, and practical examples for processing spatial data using low-code frameworks like FME and traditional GIS software.
KML To GeoJSON
Learn about converting KML to GeoJSON files, including methods, best practices, and key differences between the two spatial file formats.
Geospatial Data Integration: Best Practices
Learn about the importance of seamless integration of diverse geospatial data sources and the challenges, best practices, and workflows involved in achieving accurate mapping and analyses for decision-making.
Shapefile To GeoJSON: Best Practices
Learn three proven methods to convert shapefiles to GeoJSON for modern web mapping applications.
Digital Twin Examples
Learn how digital twin examples are reshaping manufacturing, cities, hospitals, and farms with real-time data.
Augmented Reality Databases
Learn the key database types, data requirements, and best practices for building production-ready augmented reality systems.
MCP Server Geospatial: Tutorial & Implementation
Learn how a geospatial MCP server connects AI agents to spatial tools reliably and at scale.