
AI Agent Development: Tutorial & Best Practices
Imagine having a digital helper that can plan your tasks, find information, and adapt as it goes. That’s what AI agents aim to do. At a high level, an AI agent is an autonomous system that can perceive its environment (through inputs or sensors), reason about what to do, and act on the environment to achieve specific goals. For a long time, building such agents meant hard-coding rules or using classical AI algorithms. But AI has taken a giant leap forward with the rise of large language models (LLMs).
Before the era of large language models, AI agents used more explicit logic and algorithms. Developers had to define how the agent perceives and reacts to the world in fairly strict terms. While these traditional agents can be powerful, they often adhere to predetermined rules and behavior models. Modern AI agents, by contrast, usually put a large language model (LLM) at the center of decision‐making.
In an LLM-based agent, we essentially let a pre-trained model steer the ship. Instead of explicitly coding all decisions, we prompt the model, and it generates the next action or step. One succinct definition would be: an agent can be seen as a system that uses an LLM to decide the control flow of an application. In other words, the LLM is the “brain” of the agent, deciding what to do next based on its instructions and its understanding of context.
With those fundamentals in mind, let’s dive into the core concepts you’ll need to understand and develop an AI agent.
Summary of key AI agent development concepts
The table below summarizes four key concepts related to AI agent development that this article will explore in more detail.
| Concept | Description |
|---|---|
| Understanding AI agents and their significance | AI agents are autonomous systems that perceive their environment, reason about data, and take actions using AI techniques to achieve specific goals. |
| Agent architecture components | The five building blocks that define how an AI agent senses, thinks, and acts are: • Perception • Knowledge/state • Reasoning/planning • Action • Communication |
| AI agent development frameworks | Frameworks like LangGraph, CrewAI, and FME by Safe Software provide pre-built building blocks for state management, tool integration, and orchestration. |
| Best practices for AI agent development | Several high‐level strategies to design, test, and maintain agents, spanning across scalability, prompt efficiency, monitoring, learning, integration, and ethical safeguards, can help in building reliable, production‐ready systems. |
Understanding AI agents and their significance
At its core, an AI agent is defined by its autonomy. It operates independently, making its own decisions to pursue objectives. This autonomy is what distinguishes an agent from a regular software program, which requires more human input and explicit instructions. An AI agent is given an objective and empowered with the necessary “smarts” to determine how to achieve that objective in various situations.
AI agents vs. traditional software
AI agent development requires a distinct mindset and challenges compared to traditional software development. Here are four key differences to consider:
- Dynamic decision making vs. static logic: In traditional software, you usually write explicit algorithms and fixed control flow (e.g., “if X happens, do Y”). The behavior is predetermined by your code. In contrast, an AI agent often uses a more dynamic approach. It evaluates its current state and chooses from many possible actions, or uses an AI model to decide the next step.
- Unpredictability and testing: Because AI agents can behave in nondeterministic ways, testing and debugging them can be trickier. With traditional software, a bug is usually reproducible given the same inputs. With an agent, you might get different outcomes on different runs, even with the same input, or the agent’s behavior may evolve over time.
- State and persistence: Agents are usually stateful. They maintain an internal state or memory, whether it’s a belief about the world, a conversation history, or learned parameters.
- Environment interaction: In traditional software, the “environment” is often just the program’s input/output interface (like a user interface or an API). However, agents typically operate in an environment (physical or virtual) that they can sense and change.
AI agent architecture and flow diagram
In traditional AI agent design, one often discusses the Sense–Think–Act loop: the agent senses its environment, thinks or plans, and then acts. Modern language-model agents still follow a loop but with a twist.
Instead of separating decision-making from execution, these agents use a ReAct architecture – which stands for Reasoning + Acting. They combine chain-of-thought reasoning with actions in an iterative cycle. In simple terms, the agent reasons out loud about what to do, takes an action, then observes the result and uses it to inform the next step. This creates a dynamic feedback loop rather than a one-and-done plan.
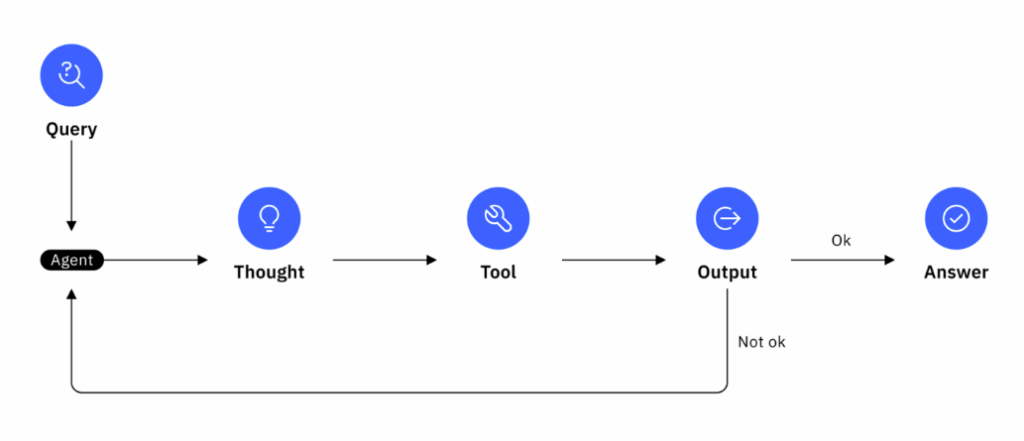
To understand the ReAct flow more concretely, let’s break down the loop into its steps:
- Query (input) – The agent observes some input or perceives the environment.
- Thought (reasoning) – The agent’s LLM thinks about the problem and the current context. This is a chain-of-thought reasoning step where the agent might, for example, plan an approach or formulate a query.
- Action (tool/API call) – Based on its thought, the agent decides on an action. This could be calling an external tool or API, querying a database, running a calculation, or any operation that helps achieve the task.
- Observation (output) – After the action, the agent gets an observation, basically the result or output of that action.
- Loop (reason → act again) – With that new observation in hand, the agent goes back to another Thought step, reasoning about what to do next. The cycle then repeats again and again. This iterative loop continues until the agent determines it has solved the problem or met the goal.
- Final answer (terminate) – Eventually, the agent’s reasoning will conclude that it has found a good answer or completed the task. At that point, instead of proposing another action, it will produce a final answer or perform a final act. This terminates the ReAct loop.
Modern LLM-based agents, therefore, tend to be more robust and adaptable thanks to this architecture. They don’t have to know everything up front; they can figure things out step by step, using tools when needed.
AI agent architecture components
Next, let’s look at the core components of general AI agent architecture and then hone in on some unique elements of LLM-based agent architecture.
Core components in agent architecture
All intelligent agents, regardless of their underlying technology, share fundamental architectural components that enable them to perceive, reason, and act in their environment.
Perception (Sensors)
The interface through which the agent observes the environment. These could be physical sensors, such as a camera or microphone, or data feeds, like incoming messages or API responses. The perception component is responsible for:
- Data collection: Gathering raw input from the environment
- Preprocessing: Converting raw sensor data into usable formats
- Feature extraction: Identifying relevant patterns or information from the input
Knowledge/state (Memory)
The information the agent keeps internally about the world or itself. This can include the agent’s beliefs about the environment’s state, the facts it has learned, or the history of interactions (such as a conversation log). Memory can be:
- Short-term memory: Ephemeral context that the agent uses within a session
- Long-term memory: Stored knowledge across sessions
- Working memory: Temporarily held information during active reasoning processes
Reasoning and Planning (Brain)
The decision-making unit that processes information and determines actions. In classical agents, this might be a set of if-then rules or a search algorithm that figures out a plan to reach a goal. In modern agents, the “brain” could be:
- Rule-based systems: Explicit conditional logic
- Machine learning models: Neural networks, policy networks in reinforcement learning
- Hybrid approaches: Combination of symbolic and connectionist methods
- Planning algorithms: Search-based methods for goal achievement
Action (Actuators/Effectors)
The mechanisms by which the agent influences the environment. These enable the agent to execute its decisions and create change in the world:
- Software agents: API calls, database operations, UI interactions
- Physical robots: Wheels, arms, speakers, or other mechanical components
- Virtual agents: Screen manipulation, file operations, network communications
Communication Interface
If the agent is part of a multi-agent system or interacts with humans, it may have a communication module. This can be considered a specialized sensor/actuator pair for messaging, including:
- Protocol Handling: Managing different communication standards
- Message Parsing: Understanding incoming communications
- Response Generation: Formulating appropriate replies
Components for LLM-based agents
When building agents powered by LLMs, some additional specialized components and concepts extend the basic AI agent architecture.
Base Model (LLM “Brain”)
The core intelligence of an LLM-based agent is the language model itself, for example, OpenAI’s GPT-4, Anthropic’s Claude, or a local model like Llama 3. This model comes pre-trained on vast amounts of text and can generate responses, reasoning steps, or other text outputs. Key characteristics of these LLM base models are:
- Pre-trained knowledge: Vast understanding of language, facts, and reasoning patterns
- Generative capabilities: Can produce coherent text responses and reasoning chains
- Context processing: Ability to understand and respond to complex, multi-turn conversations
Prompt Engineering (System Instructions)
Along with picking a model, how you prompt it is key. The prompt you give (often including a system prompt or instructions) is similar to the agent’s policy or strategy, described in words. Don’t forget to include the following for effective prompting:
- Role definition: Clearly stating what the agent is and its purpose
- Behavioral guidelines: What it should or shouldn’t do
- Output formatting: How to structure responses
- Example interactions: Demonstrating desired behavior patterns
Example: “You are an assistant agent who can use tools. Always reason step-by-step. When you need information, output a command like: SEARCH[query].”
Memory Management
LLMs have a context window limit, meaning they can only pay attention to a certain amount of text at once. This creates unique memory challenges that require sophisticated solutions.
Short-term memory is managed by carefully deciding what information to include in the prompt. This includes selecting the most relevant recent conversation history that provides necessary context for the current interaction, identifying current context information that is pertinent to the immediate task at hand, and tracking active goals, including current objectives and progress made toward achieving them. The key challenge is balancing comprehensiveness with the model’s context window limitations.
Long-term memory is handled differently. To overcome context limitations, agents integrate external storage systems that extend their memory capabilities beyond the immediate conversation. Vector databases enable semantic search and retrieval of relevant information based on meaning rather than exact keyword matches. Traditional databases provide structured data storage and retrieval for factual information, user preferences, and historical interactions. File systems serve as repositories for document storage and knowledge bases that the agent can reference when needed. Memory indexing systems create efficient pathways for locating and retrieving stored information quickly.
Tool Use and Integration
Integrating tool use extends an LLM agent’s capabilities beyond text generation, allowing it to interact with external systems and perform actions in the real world. Some common tool categories that you can easily integrate into your AI agent can be:
- Information retrieval: Web search, database queries, document lookup
- Communication: Email, messaging, API calls to external services
- File operations: Reading, writing, and manipulating files
- Creative tools: Image generation, code execution, multimedia processing
Bonus: Model Context Protocol (MCP)
Some frameworks follow a Model Context Protocol (MCP) to standardize how tool calls and their results are represented in the conversation:
- Standardized formats: Consistent representation of tool calls and responses
- Context synchronization: Ensuring model and tools stay aligned
- Extensibility: Easy addition of new capabilities without breaking existing prompt formats
- Error reporting: Structured handling of tool execution failures
Now that we’ve covered these components, let’s move on to using frameworks that help implement them.
AI agent development frameworks
Building an AI agent from scratch can be complex, but the good news is you don’t have to start from zero. There are frameworks and libraries designed to simplify the process by providing the “glue” code and abstractions for common patterns.
In this section, we’ll look at three example approaches/frameworks, each with its own philosophy and strengths: LangGraph, Crew AI, and FME. Let’s explore each in turn.
LangGraph
LangGraph is an open-source Python framework (built as an extension to LangChain) that enables developers to create stateful, multi-step agent workflows using a graph structure. It shines when you have an agent that isn’t just a single prompt-response cycle but involves multiple interconnected steps or even multiple sub-agents working together.
In LangGraph, you define a directed graph where nodes represent units of computation (like calling an LLM, executing a tool, branching logic, etc.), and edges represent the flow of information or control between those nodes. The framework then handles the orchestration of this graph, including maintaining the agent’s state and looping through nodes as needed.
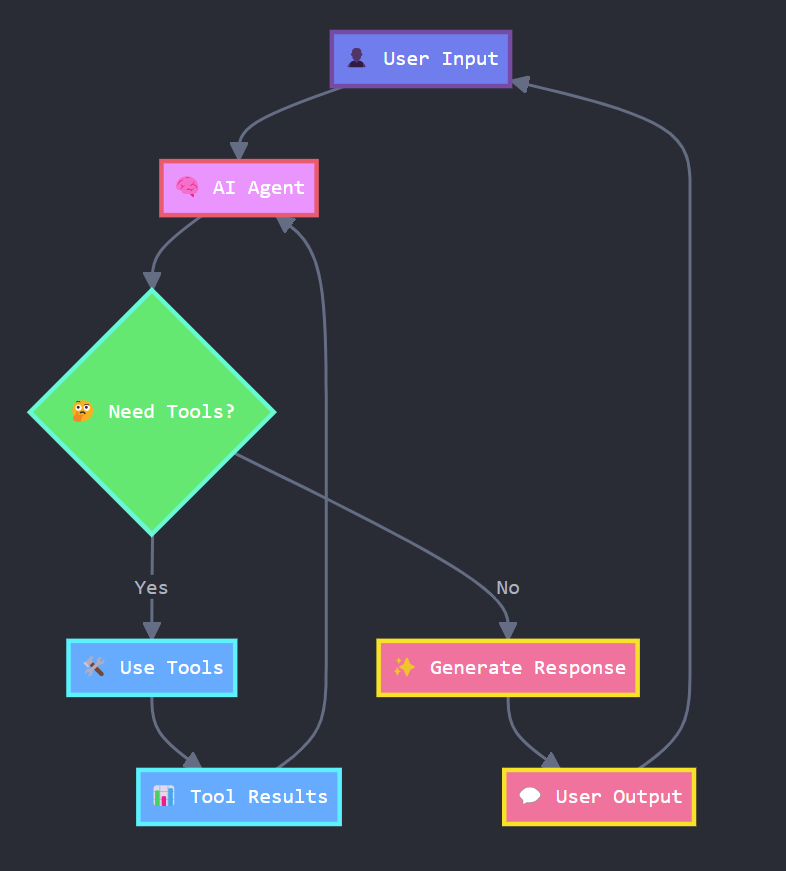
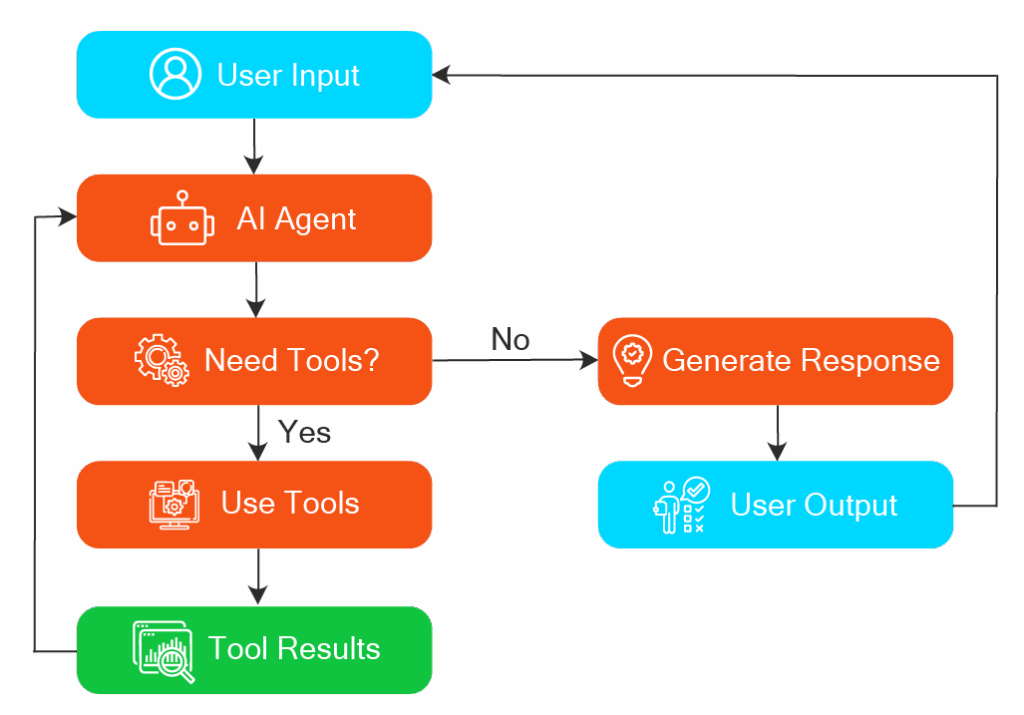
When to Use LangGraph
If you need a lot of flexibility in designing an agent’s reasoning process, LangGraph is a great choice. It’s beneficial for complex workflows. For example, an agent that must alternate between two modes (like answering questions and summarizing a document), or an agent that supervises a team of sub-agents.
Example Use Case
Imagine we want to build a Q&A chatbot agent that tries to answer user questions but, if it doesn’t know the answer, will use a web search tool to find information. We could design a simple LangGraph for this: one node uses the LLM to attempt an answer (and also to decide when it should invoke a tool), and another node is a tool node that actually performs the web search. We add a conditional edge between them so that if the answer node decides a tool is needed, the flow goes to the search node, and then the results loop back into the answer node for another try. This loop continues until the question is answered.
Pros and Cons of LangGraph
- Pros: It’s very flexible, in the sense that you can implement almost any agent logic (sequential, branching, looping, parallel).
- Cons: You need to understand the graph paradigm and the LangGraph API. The code can become complex for large graphs, and debugging an agent graph might be non-trivial.
Crew AI
Crew AI is an open-source Python framework designed specifically for creating and managing multi-agent systems. Think of it as a way to organize a team (a “crew”) of AI agents that collaborate on tasks. In Crew AI, you define multiple agents, give each a role or specialty, and set up how they interact or pass tasks among each other. The framework handles the coordination and messaging between agents, taking care of a lot of the boilerplate needed to get agents working in concert. Crew AI is built on top of LangChain and similar tools, but provides a higher-level abstraction for orchestrating several agents together.
When to Use Crew AI
If your application naturally involves multiple AI agents interacting (or agents plus human overseer roles), Crew AI can be very helpful. For example, imagine a scenario where one agent generates a plan, another agent executes the steps of the plan, and a third agent reviews the results. Crew AI lets you define those as separate agents and manage the flow between them. Another example: a simulation or game with different agents playing different roles (like buyer and seller agents in a marketplace) that need to communicate. Crew AI is ideal for such cases because it gives you a structured way to define each agent’s behavior (each agent can have its own goal, its own LLM or tools) and then a manager or environment to coordinate them. It also shines in complex workflows where you want to break a task into specialized sub-tasks handled by different “personas” or components.
Example Use Case
Let’s create a two-agent pipeline that scrapes a web page, indexes its content, and then drafts and fact-checks an answer. You load your OpenAI API key and then use ScrapeWebsiteTool to grab the text of Wikipedia’s “Generative Artificial Intelligence” article. You clean it to ASCII and save it with FileWriterTool, then wrap it in a TXTSearchTool so your agents can query it efficiently.
Now it’s time to define your agents:
- Educator – You ask this agent to generate an initial definition of “What is Generative AI?” based on the indexed context.
- FactChecker – You task this agent with re-querying the same file to verify every claim the Educator makes, suggesting corrections or clarifications where needed.
You package each role into its own Task, bundle them into a Crew, and invoke crew.kickoff(). In return, you get a polished, fact-checked definition ready for publication. This approach lets you prototype reliable, modular AI workflows in any domain.
Let’s explore the code by examining each section closely.
- Load and Configure Your API Key
First, we load any environment variables (like your OpenAI key) from a .env file, then assign it to os.environ so our agents can authenticate securely when they make LLM calls.
from crewai_tools import ScrapeWebsiteTool, FileWriterTool, TXTSearchTool
from crewai import Agent, Task, Crew
import os
from dotenv import load_dotenv
# 1) Load your OpenAI key
load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv('OPENAI_API_KEY')- Scrape and Clean the Web Page
Next, we instantiate ScrapeWebsiteTool to fetch the raw HTML/text of the Wikipedia page on “Generative artificial intelligence.” Once we have raw_text, we strip out any non-ASCII characters and save it to disk.
# 2) Scrape the AI page
scraper = ScrapeWebsiteTool(website_url='https://en.wikipedia.org/wiki/Generative_artificial_intelligence')
raw_text = scraper.run()
# Save to disk (ASCII only)
file_writer = FileWriterTool()
clean_text = raw_text.encode("ascii", "ignore").decode()
file_writer._run(filename='mytext.txt', content=clean_text, overwrite="True")- Create a Searchable Index Over the Saved File
With mytext.txt on disk, we now create a TXTSearchTool so our agents can efficiently query the content. Under the hood, this usually builds a simple text index or uses a library like FAISS to let “search” run fast.
# 3) Make a search tool over that file
search_tool = TXTSearchTool(txt='mytext.txt')
# Pull initial context for the question (pass via the required kwarg)
initial_context = search_tool.run(
search_query="What is Generative AI?"
)- Define the Educator Agent
Now that we can look up “Generative AI” in the saved text, let’s let our Educator agent craft the first draft of a definition. We pass it:
- role=’Educator’ (just a label, but some UI/UX layers might show it)
- goal= … (a string prompt telling it exactly what to do, including the “Context” from our search)
- role=’Educator’ (just a label, but some UI/UX layers might show it)
- tools=[search_tool] (the only tool this agent can call is our local text-search)
# 4) Educator agent: crafts the first answer
educator = Agent(
role='Educator',
goal=(
f'Based on the context provided, answer “"What is Generative AI?” '
f'Context:\n{initial_context}'
),
backstory='You are a data expert.',
verbose=True,
allow_delegation=False,
tools=[search_tool]
)- Define the FactChecker Agent
Once the Educator has sketched out its definition, we want a second agent, FactChecker, to comb through that answer and validate every claim. The FactChecker uses exactly the same text index, so it can re-query “Generative AI” or dive deeper wherever doubts arise.
# 5) FactChecker agent: reviews and refines the Educator’s answer
# It can re‐query the same file to double‐check definitions or examples.
fact_checker = Agent(
role='FactChecker',
goal=(
'Review the Educator’s answer for accuracy and completeness. '
'Use the same ai.txt context to verify any statements and '
'suggest corrections or clarifications if needed.'
),
backstory='You are a meticulous fact‐checker.',
verbose=True,
allow_delegation=False,
tools=[search_tool]
)- Wrap Each Agent Into a Task
Every agent needs a Task that packages:
- A description (what we expect this agent to do),
- The list of tools it may invoke,
- A pointer to the agent object itself,
- An expected_output string (a brief note for human readers).
# 6) Define tasks for each agent
educator_task = Task(
description="Generate an initial definition of Generative AI",
tools=[search_tool],
agent=educator,
expected_output='A clear, context‐grounded definition of Generative AI'
)
factcheck_task = Task(
description="Validate and refine the definition",
tools=[search_tool],
agent=fact_checker,
expected_output='A fact‐checked, refined version of the definition'
)- Bundle Agents and Tasks Into a Crew
A Crew is simply a collection of agents + their tasks. When you call crew.kickoff(), Crew AI coordinates:
- Running Educator to produce the first answer,
- Piping Educator’s answer into FactChecker,
- Returning the final, polished output.
# 9) Kick off both agents in one Crew
crew = Crew(
agents=[educator, fact_checker],
tasks=[educator_task, factcheck_task]
)- Run the Crew and Retrieve Results
Finally, we launch the entire multi-agent workflow with a single method call: crew.kickoff(). It returns a dictionary (or list) of each agent’s output. In this example, we’ll print everything to the console.
# 8) Run and print all outputs
outputs = crew.kickoff()
print("Outputs from the Crew:")
print(outputs)Output:
‘Educator’ agent gets invoked and displays its intermittent thoughts and input/output.
# Agent: Educator
## Thought: Action: Search a txt's content
## Using tool: Search a txt's content
## Tool Input:
"{\"description\": \"What is Generative AI?\", \"type\": \"str\"}"
## Tool Output:
Tool Search a txt's content accepts these inputs: Tool Name: Search a txt's content
Tool Arguments: {'search_query': {'description': "Mandatory search query you want to use to search the txt's content", 'type': 'str'}}
Tool Description: A tool that can be used to semantic search a query the mytext.txt txt's content..
Moving on then. I MUST either use a tool (use one at time) OR give my best final answer not both at the same time. When responding, I must use the following format:
```
Thought: you should always think about what to do
Action: the action to take, should be one of [Search a txt's content]
Action Input: the input to the action, dictionary enclosed in curly braces
Observation: the result of the action
```
This Thought/Action/Action Input/Result can repeat N times. Once I know the final answer, I must return the following format:
```
Thought: I now can give a great answer
Final Answer: Your final answer must be the great and the most complete as possible, it must be outcome described
```
# Agent: Educator
## Final Answer:
Generative artificial intelligence (Generative AI, GenAI, or GAI) is a specialized subfield of artificial intelligence that employs generative models to generate various forms of content including text, images, videos, and more. These models are trained on large datasets to understand and learn the patterns and structures inherent in the data, allowing them to produce new, original outputs based on specific input prompts, often articulated in natural language. In recent years, especially during the AI boom of the 2020s, generative AI technologies have become increasingly prominent, driven by advancements in transformer-based deep neural networks, particularly through large language models (LLMs). Key generative AI applications include chatbots like ChatGPT, image generation systems like DALL-E and Stable Diffusion, as well as text-to-video generation tools. However, the rise of generative AI has also sparked significant ethical discussions, particularly concerning its potential misuse in cybercrime, proliferation of misinformation, job displacement, and implications for intellectual property rights.‘FactChecker’ agent gets invoked and displays its intermittent thoughts and input/output.
# Agent: FactChecker
## Thought: Thought: I need to validate the definition of generative artificial intelligence accurately.
## Using tool: Search a txt's content
## Tool Input:
"{\"search_query\": \"Generative artificial intelligence definition\"}"
## Tool Output:
Relevant Content:
Generative artificial intelligence (Generative AI, GenAI, [ 167 ] or GAI) is a subfield of artificial intelligence that uses generative models to produce text, images, videos, or other forms of data. [ 168 ] [ 169 ] [ 170 ] These models learn the underlying patterns and structures of their training data and use them to produce new data [ 171 ] [ 172 ] based on the input, which often comes in the form of natural language prompts . [ 173 ] [ 174 ]
Generative AI tools have become more common since an " AI boom " in the 2020s. This boom was made possible by improvements in transformer -based deep neural networks , particularly large language models (LLMs). Major tools include chatbots such as ChatGPT , DeepSeek , Copilot , Gemini , and LLaMA ; text-to-image artificial intelligence image generation systems such as Stable Diffusion , Midjourney , and DALL-E ; and text-to-video AI generators such as Sora . [ 175 ] [ 176 ] [ 177 ] [ 178 ] Technology companies developing generative AI include OpenAI , Anthropic , Microsoft , Google , DeepSeek , and Baidu . [ 179 ] [ 180 ] [ 181 ]
Generative AI has raised many ethical questions. It can be used for cybercrime , or to deceive or manipulate people through fake news or deepfakes . [ 182 ] Even if used ethically, it may lead to the mass replacement of human jobs . [ 183 ] The tools themselves have been criticized as violating intellectual property laws, since they are trained on and emulate copyrighted works of art. [ 184 ]
AgentsThe final response is returned back to the user.
# Agent: FactChecker
## Final Answer:
Generative artificial intelligence (Generative AI, GenAI, or GAI) is a specialized subfield of artificial intelligence that utilizes generative models to create various forms of content, including text, images, videos, and more. These models are trained on extensive datasets, allowing them to learn and understand inherent patterns and structures within the data. Consequently, they can produce new, original outputs based on specific input prompts, which are often articulated in natural language. The prominence of generative AI has surged, especially during the AI boom of the 2020s, fueled by advancements in transformer-based deep neural networks, particularly through large language models (LLMs). Notable applications of generative AI include chatbots like ChatGPT, image-generation systems such as DALL-E and Stable Diffusion, as well as text-to-video generation tools. However, the rise of generative AI also raises substantial ethical discussions regarding its potential for misuse in cybercrime, the proliferation of misinformation, job displacement, and implications related to intellectual property rights.
Outputs from the Crew:
Generative artificial intelligence (Generative AI, GenAI, or GAI) is a specialized subfield of artificial intelligence that utilizes generative models to create various forms of content, including text, images, videos, and more. These models are trained on extensive datasets, allowing them to learn and understand inherent patterns and structures within the data. Consequently, they can produce new, original outputs based on specific input prompts, which are often articulated in natural language. The prominence of generative AI has surged, especially during the AI boom of the 2020s, fueled by advancements in transformer-based deep neural networks, particularly through large language models (LLMs). Notable applications of generative AI include chatbots like ChatGPT, image-generation systems such as DALL-E and Stable Diffusion, as well as text-to-video generation tools. However, the rise of generative AI also raises substantial ethical discussions regarding its potential for misuse in cybercrime, the proliferation of misinformation, job displacement, and implications related to intellectual property rights.Pros and Cons of Crew AI
- Pros: Crew AI simplifies multi-agent orchestration
- Cons: Using multiple agents introduces complexity in understanding the overall flow
FME by Safe (No-code agent builder)
While LangGraph and Crew AI give you powerful, code-first ways to build agents, they do require solid programming chops. If you’d rather assemble AI workflows visually instead of writing lots of boilerplate, a no-code platform can be a great alternative. FME lets you drag, drop, and link AI models, data sources, and actions into a seamless “agent” flow. Next up, we’ll take a quick look at how FME works.
FME by Safe Software is a bit different from the previous two frameworks. It’s a no-code platform traditionally used for building data workflows (e.g., ETL tasks). Recently, it has added capabilities to integrate AI models and agents into those workflows.
Essentially, FME (which stands for Feature Manipulation Engine) provides a graphical interface where you can drag and drop components to handle data and now AI logic. This allows you to create agent-like behaviors by chaining together flows of data and AI operations without writing code. You can think of FME as a visual programming tool: you have blocks (called transformers) that might do things like call an LLM or perform a database query, and you connect these blocks to form an “agent workflow.”
When to Use FME
If you are not a traditional software developer or you want to prototype an AI-driven process very quickly, FME can be a strong choice. It’s ideal in enterprise scenarios where an agent needs to integrate with numerous data sources (files, databases, APIs) because FME comes with built-in support for hundreds of formats and connectors.
For example, you can use FME to create an agent that automatically reads incoming survey responses (from a spreadsheet or form), uses an LLM to analyze the free-text feedback, and then routes the results into different databases or sends alerts – all via a visual interface, no coding required. It’s also great for workflows that are relatively linear or data-processing-heavy, where you might not need complex conditional loops but do need to shuffle data between many systems. Safe Software markets FME with the slogan “All Data, Any AI,” meaning it tries to let you use any AI model (OpenAI, Azure AI, local models, etc.) and any data source together in one pipeline.
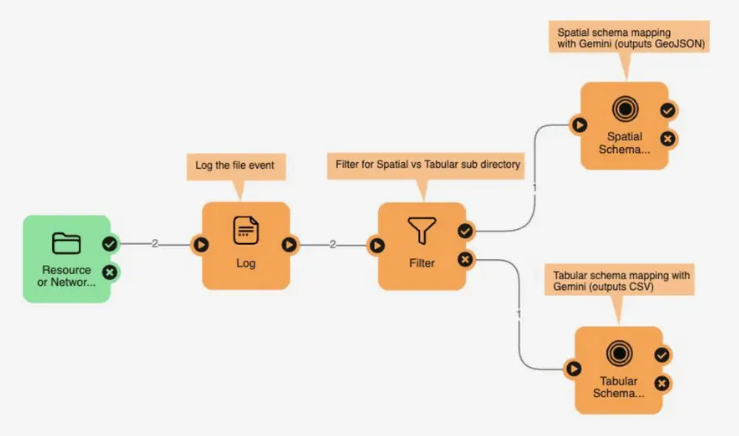
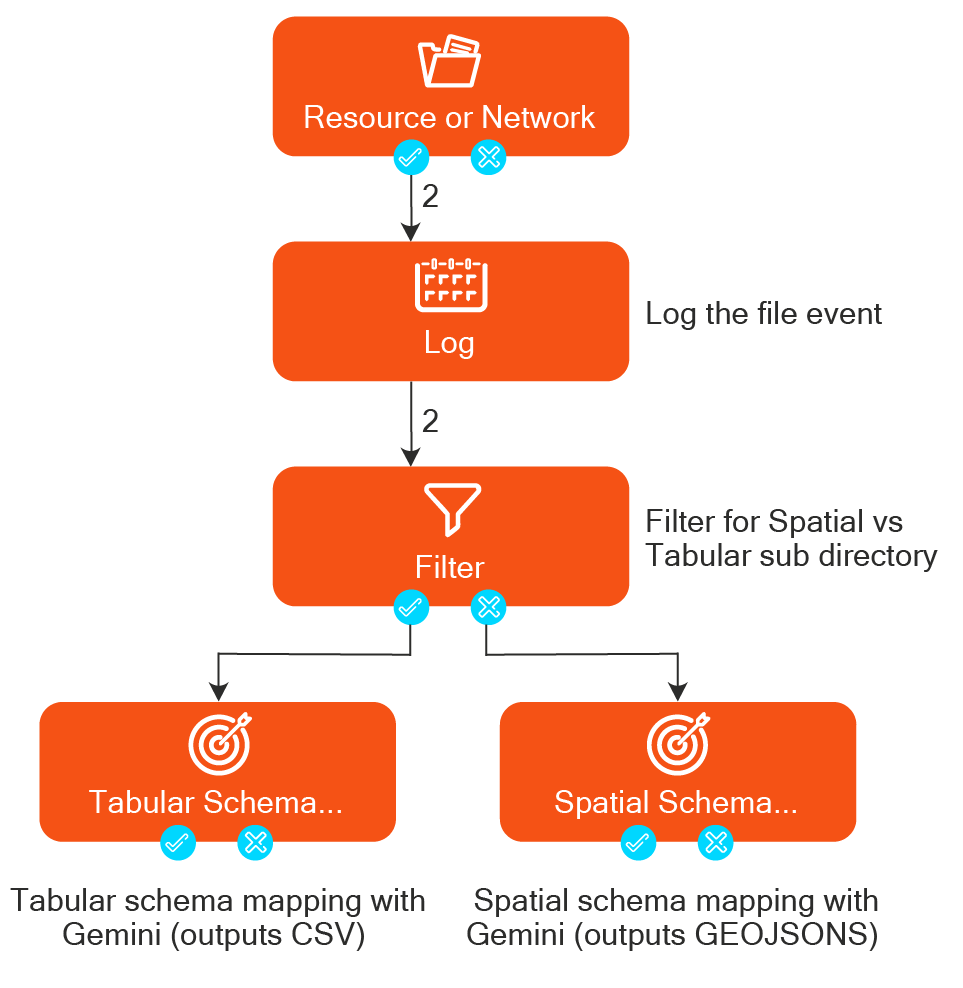
Example Use Case
Suppose we want to build a simple agent that processes customer support emails and meets these requirements:
- Read the incoming email,
- Classify the email’s topic,
- Generate a suggested reply
In a no-code FME environment, we could chain a few transformers to accomplish this. For instance:
- Email reader – reads new emails from a mail server.
- AI text classifier (OpenAI) – takes the email text and classifies it into categories (say, Billing, Technical Support, or General Inquiry). This can be implemented using OpenAIConnector in FME.
- Branch by category – a decision block that routes the workflow based on the category output (if the email was classified as Technical, we might handle it differently than Billing).
- AI text generator (OpenAI) – generates a draft reply tailored to that category, using a prompt and the original email content. This can be implemented using OpenAIConnector in FME.
- HTML Output – Writes out the suggested reply as HTML to send out.
Implementing the above logic will look as follows in FME
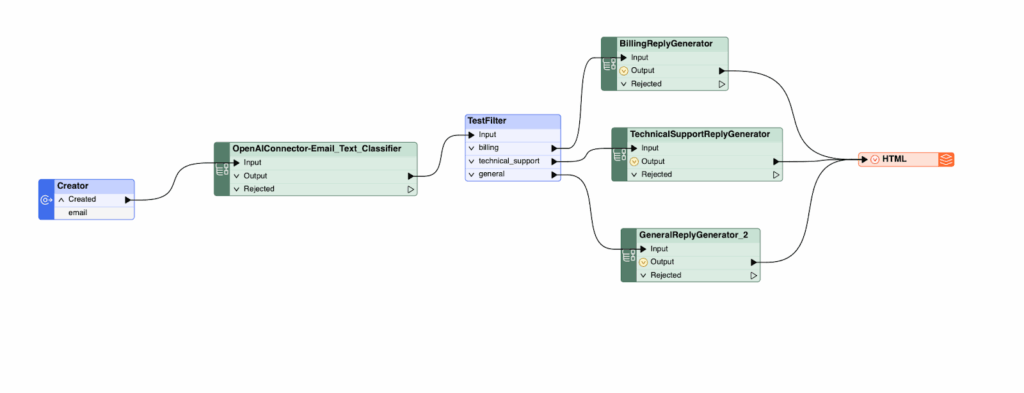
To run the above sequence, one can download the file from FME Workbench and upload it to FME Flow, a cloud-hosted runtime. FME flow will help users to run and monitor the flow.
Pros and Cons of FME
- Pros: The no-code, user-friendly approach is great for those who aren’t comfortable with Python or writing complex logic.
- Cons: No-code platforms, while powerful, offer less flexibility for complex logic.
Below is a brief wrap‐up highlighting how LangGraph, Crew AI, and FME align and differ across key dimensions.
| Framework | Type | Primary Use Cases | Flexibility | Learning Curve | Integration Complexity |
|---|---|---|---|---|---|
| LangGraph | Code‐centric (Python) | Complex, custom agent workflows (branching, loops, parallel) | Very high (fully programmable graph) | Moderate to steep (graph API + prompt engineering) | High (you write most logic yourself, but can tap into LangChain tools) |
| Crew AI | Python library | Orchestrating multiple specialized agents (educator/fact‐checker, buyer/seller, etc.) | Medium (pre‐wired agent/task abstractions) | Gentle to moderate (Task/Agent/Tool patterns) | Medium (framework handles messaging; you supply agents + tasks) |
| FME | No-code/visual | Data‐driven pipelines with AI steps (ETL + LLM/Text analysis) | Limited (preconfigured connectors, drag-drop) | Low (UI‐driven, minimal coding) | Low to medium (connectors handle data sources, but custom logic is constrained) |
Seven best practices for AI agent development
Beyond understanding concepts and using frameworks, you should follow best practices to ensure your agents are robust, scalable, and behave ethically. Below are seven recommendations for AI agent development that should be applied when building production and user-facing agents.
Scale Smart
It’s tempting to throw in a dozen tools and complex multi-agent setups from the start. But that increases complexity and potential points of failure. Begin with a minimal viable agent and verify it works end-to-end.
If your agent will serve many users or run continuously, consider:
- How will it scale out in deployment
- Using caching where possible
- Rate limits for cloud APIs (like OpenAI)
- Implementing queuing or backpressure when needed
Design for scale by leveraging good software architecture patterns. Consider stateless vs stateful services and horizontal scaling as appropriate.
Optimize Prompt Length
Every extra token adds cost and latency to your AI’s response. Avoid packing multiple requests into one giant query. Instead of one massive prompt, use smaller, step-by-step prompts. This lets the model tackle problems one piece at a time. It keeps interactions efficient and makes debugging easier.
Sending more text than the model can handle may result in:
- Errors or truncated outputs
- Request failures
- Unexpected behavior
Monitor your token usage with counting tools. Stay within allowed limits to prevent problems.
Test Thoroughly
AI agents can be unpredictable. Nondeterministic behavior makes testing crucial but tricky. Create test scenarios covering typical use cases, edge cases, error conditions, and various input types and lengths. For instance, if you build a chatbot agent, test it on straightforward factual questions, nonsensical inputs, and extremely long messages.
Include human feedback in your testing process. Automated tests might miss issues like off-putting tone, misunderstanding common phrases, or poor user experience. Even informal testing with colleagues can reveal problems that automated tests miss. Human testers provide insight into whether the agent is actually helpful and pleasant to interact with.
Monitor and Iterate
Once your agent is deployed, track:
- Each decision it makes
- Errors encountered
- Key metrics like response time
- Task success rate
If you have an agent handling customer orders, log how often it successfully completes orders versus failures or human handoffs. An agent might work correctly but be slow or resource-intensive. Keep an eye on:
- CPU and memory usage
- Number of API calls to the LLM
- Cost implications
- User experience impact
Monitoring helps catch real-time issues and provides data for continuous improvement.
Enable Continuous Learning
Make a practice to gather feedback systematically. For user-facing agents, prompt users occasionally with questions like “Did that answer your question?” and record feedback patterns. Use this data to refine prompts and rules. For internal agents, log actions and success rates, then periodically review logs to find failure patterns.
Consider automated learning approaches. You might use reinforcement learning from human feedback (RLHF) when feasible, or implement runtime learning through long-term memory updates. After successfully handling novel scenarios, add them to the agent’s knowledge base for future reference.
You also need to keep knowledge sources current. Regularly update documents the agent relies on, FAQs and knowledge bases, and external databases. An agent is only as good as the information it has access to.
Integrate Carefully
Treat your agent as a proper service. Integration is where many practical issues arise. Your agent should have well-defined inputs and outputs, clear interfaces with other systems, and proper error handling and validation.
Handling external dependencies robustly is also extremely crucial. When integrating with tools, databases, or APIs, detect failures and implement retry logic. Return friendly error messages instead of crashing. Add extra logging around integration points and plan for network failures, bad data, and timeouts.
Follow service integration best practices. Define clear interfaces, validate inputs and outputs, handle real-world issues like security threats, and plan for the unexpected. Treat integration like you would any other service in your architecture.
Ensure Ethical and Safe Behavior
Use content filtering to block hate speech, bias, and disallowed material before it reaches users. This is your first line of defense against problematic responses.
Be transparent about the nature of AI. Let users know they’re interacting with an AI, especially when it calls external tools, fetches information, or accesses user data. Simple messages like “I’m checking my sources now…” help maintain transparency.
Don’t forget to build safety nets for real-world actions. When agents perform important tasks, they require human approval for critical actions like mass emails or financial transactions. Limit agent permissions to only necessary tasks and implement approval workflows for high-impact decisions. Strip out or anonymize sensitive details and share only the minimum information needed with external services. Follow data privacy regulations and implement proper data hygiene practices.
Together, these measures, content moderation, clear disclosure, human-in-the-loop, and strict data hygiene, help your agent behave responsibly and earn user trust.
Conclusion
Each approach and example we’ve discussed, whether it’s the structured power of LangGraph, the multi-agent coordination of Crew AI, or the ease-of-use of FME, shows that you don’t have to reinvent the wheel to create capable AI agents.
As you venture into your own AI agent projects, keep the best practices we covered in mind. These practices will save you headaches and make your agents more reliable and trustworthy.
AI agents represent a new frontier where software is not just coded, but taught or guided into performing tasks. Diving into agent development can accelerate your understanding of AI and open up possibilities to build applications that feel very futuristic, like personal assistants, smart automation tools, or game characters with human-like depth. The key is to maintain a balance between the agent’s autonomy and your control over its behavior. Use the traditional approaches to keep it grounded, and the new LLM-based approaches to give it wings. Happy coding, and may your agents always work for you, not against you!
Continue reading this series
AI Agent Architecture: Tutorial & Examples
Learn the key components and architectural concepts behind AI agents, including LLMs, memory, functions, and routing, as well as best practices for implementation.
AI Agentic Workflows: Tutorial & Best Practices
Learn about the key design patterns for building AI agents and agentic workflows, and the best practices for building them using code-based frameworks and no-code platforms.
AI Agent Routing: Tutorial & Examples
Learn about the crucial role of AI agent routing in designing a scalable, extensible, and cost-effective AI system using various design patterns and best practices.
AI Agent Development: Tutorial & Best Practices
Learn about the development and significance of AI agents, using large language models to steer autonomous systems towards specific goals.
AI Agent Platform: Tutorial & Must-Have Features
Learn how AI agents, powered by LLMs, can perform tasks independently and how to choose the right platform for your needs.
AI Agent Use Cases
Learn the basics of implementing AI agents with agentic frameworks and how they revolutionize industries through autonomous decision-making and intelligent systems.
AI Agent Tools: Tutorial & Example
Learn about the capabilities and best practices for implementing tool-calling AI agents, including a Python-based LangGraph example and leveraging FME by Safe for no-code solutions.
AI Agent Examples
Learn about the core architecture and functionality of AI agents, including their key components and real-world examples, to understand how they can complete tasks autonomously.
No Code AI Agent Builder
Learn the benefits and limitations of no-code AI agent builders and how they democratize AI adoption for businesses, as well as the key components and features of these platforms.
Multi-Agent Systems: Implementation Best Practices
Learn about multi-agent systems and how they improve upon single-agent workflows in handling complex tasks with specialised roles, communication, coordination, and orchestration.
Langgraph Alternatives: The Top 6 Choices
Learn about LangGraph, a powerful yet complex orchestration framework for building intelligent systems, and its limitations, alternatives, and selection criteria.
Agentic AI vs Generative AI
Learn the differences between generative AI and agentic AI and how to choose the right AI paradigm for your needs.