Understanding XML: The Human’s Guide to Machine-Readable Data

Data formats are designed to be either machine readable (structured so computers can process it) or human readable (easy for humans to understand). Some formats, like XML and JSON, are allegedly both. Let’s call these ambivert formats. This means when you, a human, open the file, you can read what’s inside — but the data is still structured and therefore optimized for machine processing.
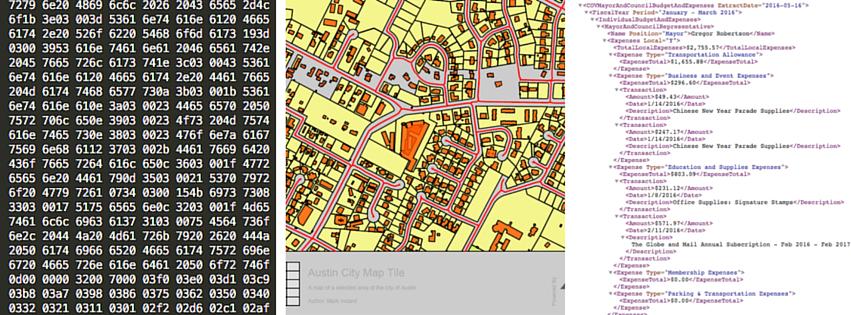
Ambivert formats like XML, JSON, and GML are the language of the web, mobile, and REST APIs. The syntax is so powerful and versatile that it has become the basis for hundreds of formats, from desktop tools to data exchange over the web.
The Problem with Ambivert Formats
Just because a format is classified as “human-readable” doesn’t mean it’s understandable. Yes, I can read this JSON snippet:
{“name”:”Electric Vehicle Charging Stations”,”type”:”FeatureCollection” ,”crs”:{
“type”:”name”,”properties”:{“name”:”EPSG:26910″}} ,”features”:[ {“type”:”Feature”
,”geometry”:{“type”:”Point”,”coordinates”:[492699.273158735,5452194.867862]}
,”properties”:{“LOT_OPERATOR”:”City of Vancouver”,”ADDRESS”:”6810 Main Street”}}
… but it’s not exactly understandable. If it was truly human-readable, the data would look like this:
This file contains 32 points representing electric vehicle charging stations
in Vancouver. The first station is located at latitude 49.22249551, longitude
-123.1002624, is operated by the City of Vancouver, and the address is
6810 Main Street. The second …
How can we quickly and easily understand data that’s optimized for machines? Beyond that, how can we work with it in advanced ways? Often, we need to use XML to exchange highly structured data with other applications it was not originally intended for.

Understanding Any XML-Based Data
The key is to leverage automation where you can. In other words, get a machine to parse the data before you try to gather useful information from it.
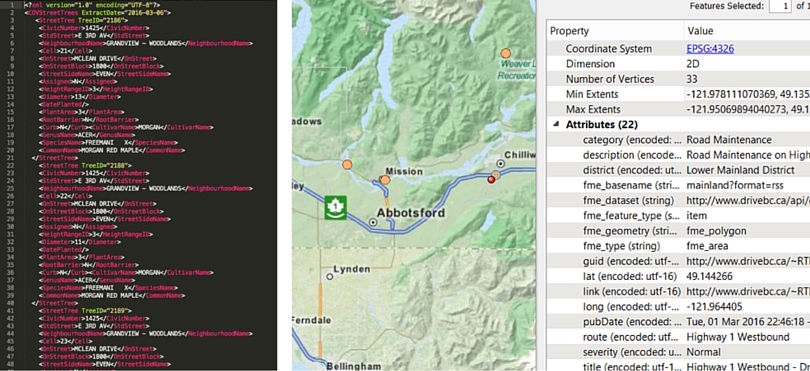
Automating the hard part — interpreting the syntax — frees you to work with the attributes like any other data type. Here are a few automations that make it easier to understand these formats. These are new features we added in FME 2016, with the goal that users shouldn’t need to know anything about XML, GML, or JSON to read these data sources (or to write to them, or modify, map, template, update, validate, or any other transformations).
Working with XML Hierarchies
Understanding XML starts with presenting the data’s hierarchical structure in a straightforward way. In FME, the tree navigation interface lets you choose which XML node you want to become a feature type (or layer or feature class). Then the fields are auto-generated. Using the data in your workflow becomes simple — for example to create geometry out of lat/long and georeference the data points.
Working with Nested JSON
JSON doesn’t have XML’s schema complexities, but it can be highly nested. This often means counting brackets and braces and trying to write complicated JSON queries. The solution: automatically flatten JSON into features and parse common forms into attributes. We introduced an automatic schema scan mode to FME’s JSON reader for this. From there, you can work with the features and attributes in a human-friendly interface. (And like XML hierarchies, we are also planning to add a tree navigation UI in the next FME release.)
Working with Schemaless GML/WFS
Often, your GML schema is in a separate .xsd file, and that doc is missing. Now what? When you don’t need to know the GML schema, don’t worry about it. We added an ignore schema mode to FME so you can read almost any GML. While a schema is still needed to write and validate GML, in cases where the exact schema isn’t critical (e.g. going from GML to GIS) it’s helpful to be able to ignore it.
*
The moral of the story: Make your computer do the hard part and interpret XML/JSON syntax for you. Once you’re able to understand what’s going on inside an XML-based dataset, you can better use it in your data integration and automation scenarios. You could even build your own web services!
If you want to learn more about working with XML, GML and JSON, we have lots of resources:
- JSON Webinar
- GML Webinar
- Achieving INSPIRE compliance
- XML tutorial on the FME Knowledge Center
XML problems? Send us a note at xml@safe.com. Our co-founder, Don Murray (XML’s #1 fan), reads these emails and will get back to you.


