
When I think about Big Data, I immediately think of the cloud and Amazon Web Services. When it comes to big data the AWS service that I am most excited about is Amazon’s DynamoDB. Amazon DynamoDB is a cloud-based, NoSQL database that was designed from the ground up to support Big Data.
After reading Yosuke Matsua’s Geo Library for Amazon DynamoDB blog posts I was inspired to build on his approach. Building on the geohashing concept and using our new support for DynamoDB, I developed a technique to store not just points but also lines, polygons, raster, LiDAR, and anything else with location, or to which location could be associated.
 Amazon DynamoDB and Amazon S3: A Powerful Pair
Amazon DynamoDB and Amazon S3: A Powerful Pair

DynamoDB and S3 are a powerful pair for storing all types of information. DynamoDB is a flexible NoSQL database that I use for storing small features, metadata and index information. DynamoDB is very fast; as the data is stored on SSD’s, and resilient; as the data is replicated across many machines (and availability zones).
While a DynamoDB database can grow to any size there is a 64k limit on the size of any item that’s stored in it.
That’s where S3 comes in. S3 is great for storing documents of any size, providing a very simple storage mechanism akin to a file system. Bringing these two technologies together packs a potent punch!
One of my favourite features of S3 is that every S3 object (or document) has a web address. Using this web address, a document can be accessed with absolutely no impact on your web server or database! This is a big deal for anyone wanting to build massive, scalable, cloud-based solutions.
A Geohash-Based Index for DynamoDB
DynamoDB doesn’t have native support for spatial data. For this project I took the geohash concept introduced by Yosuke Matsua to store points and extended it to build a geohash-based index that also indexes lines (e.g. roads) and areas (e.g. political boundaries).
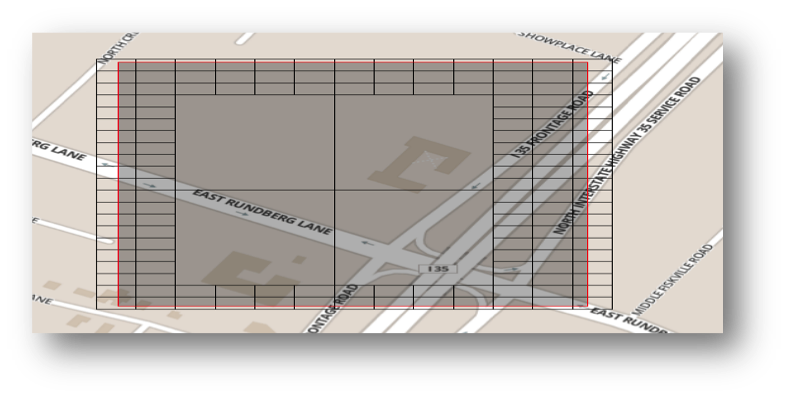
Example 1 – Storing Polygons in DynamoDB
The image below shows the geohash index records that represent arbitrary area features. Each geohash index record is written to DynamoDB.

Example 2 – Storing Linear Features in DynamoDB
Linear features are done in a similar fashion. The illustration below shows many different lines and their associated geohashes.

Example 3 – Storing Satellite or Aerial Imagery in DynamoDB
Satellite or Aerial imagery is done in a similar fashion.
As you can see, there are many geohash index records for each data record. When building the geohash index, the number of geohash records goes up by about a factor of 5 or 6 with every increase of geohash precision. It’s important to keep this in mind and find the balance to meet your needs.
Remember, the geohash indexes here are a fuzzy approximation that helps you quickly and efficiently zoom into data that is in your “area of interest”.
Store Whatever You Want and Give It a Location
Once I had built the indexing strategy as described above it was simple to store everything within this DynamoDB/S3 Big Data system.


GIS and CAD Data: Each “spatial feature” is stored directly within DynamoDB if it small. Otherwise the “spatial feature” is stored as an object in S3 with a pointer to the S3 location that’s stored in DynamoDB.


Raster and LiDAR Data: I store these datasets in S3 and build a geohash index set that approximates the footprint of the image or LiDAR scan. With LiDAR, the footprint is an arbitrary polygon.

GeoTagged Photos: The geotag information is extracted from submitted geotagged photos. The photo is then copied up to S3. The geohash for the photo is calculated and stored in DynamoDB.
Other Documents: Here I created the ability to associated any file or document with a location. While the majority of documents don’t have an explicit location stored within them, it is often useful to associate them or catalog them against a location for retrieval later.

Some example types of documents that have location information are Traffic information, Crime Scenes, Events, Buildings, Roadways, Clients, and Sensor data. Here the system simply requires a location be identified and the document is then uploaded and associated with a geohash at that location.
 Web Resources: Documents increasingly live on some cloud storage systems like Dropbox, Box.com, Google Drive, etc. So I wanted to spatially index these as well. The web resource could be a camera or sensor feed enabling organizations to also quickly index these. Indexing these is simple, with the system being passed in the web resource URI and the location. The system stores the reference to the web resource and associates it with a geohash record.
Web Resources: Documents increasingly live on some cloud storage systems like Dropbox, Box.com, Google Drive, etc. So I wanted to spatially index these as well. The web resource could be a camera or sensor feed enabling organizations to also quickly index these. Indexing these is simple, with the system being passed in the web resource URI and the location. The system stores the reference to the web resource and associates it with a geohash record.
How Exactly Did I Do This?
In my next post, I’ll give a step-by-step guide for this solution. In the meantime, check out the demo that I gave of this in a recent Big Data webinar.


