
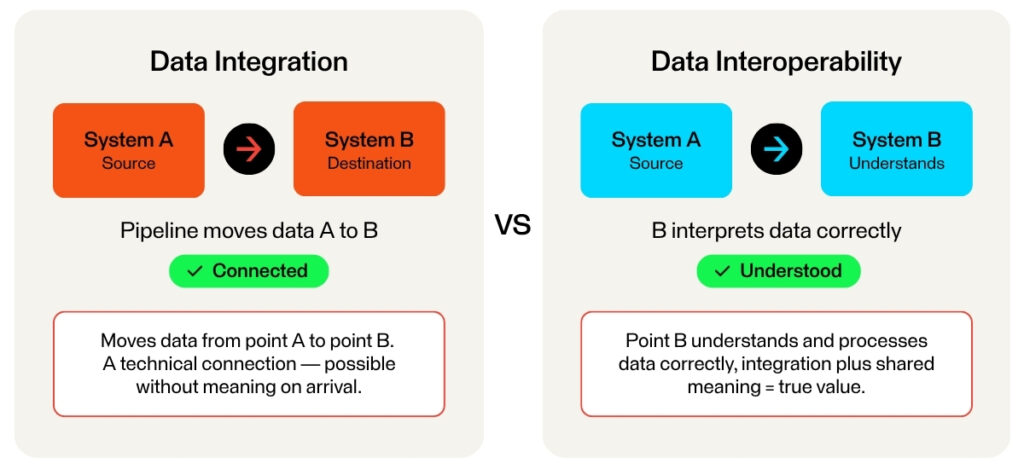
What is Data Interoperability?
While data integration is the technical connection that moves data from point A to point B, data interoperability is the ability of point B to understand and process that data correctly once it arrives. You can have integration without interoperability, such as a pipeline that delivers data in a format the receiving system cannot interpret. Such a system is technically connected but practically useless.
When systems cannot communicate meaningfully, the consequences ripple outward. Decision-making slows, innovation cycles stretch longer than they need to, and operational risk increases as teams work with fragmented, inconsistent information. For large enterprises managing dozens or hundreds of systems, these costs compound quickly.
Let’s examine the four key challenges of enterprise data interoperability:
- Data silos and legacy systems
- Schema mismatches
- API complexity
- Governance gaps
Data Silos and Legacy Systems in Enterprise Data Interoperability
The foundational challenge of enterprise data interoperability is structural: many large organizations did not build their technology stack with interoperability in mind. They built it department by department, system by system, over many years.
The result is data silos. Sales runs on one CRM, finance operates in its own ERP, the logistics team manages a separate warehouse system, and so on. Each of these platforms was chosen to solve a specific problem, and each stores its data in isolation. Information that should flow freely between teams sits locked behind departmental boundaries, requiring manual effort or custom-built workarounds to be shared.
Each decade added new systems – each in isolation, never designed to connect
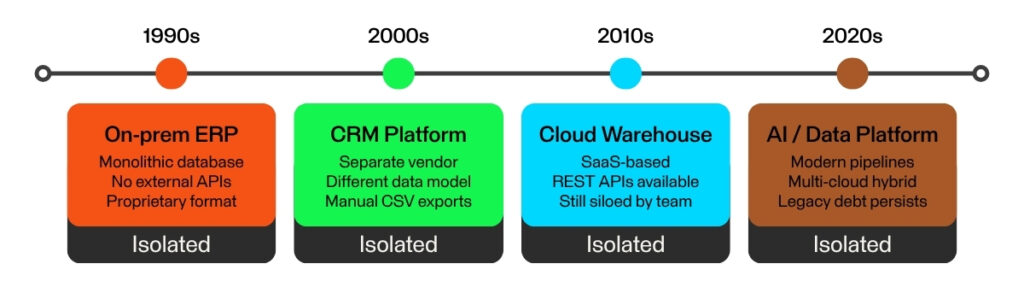
30+ years of accumulated silos – retrofitting interoperability is costly and complex
Legacy systems deepen this problem. Many older databases were architected decades ago, long before modern APIs or cloud-based data exchange were standard practice. They were not designed to expose data in real time or to communicate with external systems in any standardized way. Retrofitting them for interoperability is expensive, technically complex, and carries significant risk to systems that businesses often cannot afford to take offline.
Even when organizations are ready to migrate, the sheer volume of enterprise data presents its own obstacle. Moving or synchronizing large datasets between cloud providers, on-premises servers, or hybrid environments can be costly and complex, especially at scale or across environments. Transformation logic, latency, and consistency requirements all add friction to what might seem like a straightforward transfer.
The downstream effect of all this is a persistent lack of a single source of truth. When the same customer record exists in five different systems, each slightly different, which one is correct? That question (multiplied across every entity and transaction in an enterprise!) is why data silos are an impediment to trustworthy data.
Schema Mismatches and Data Quality Issues
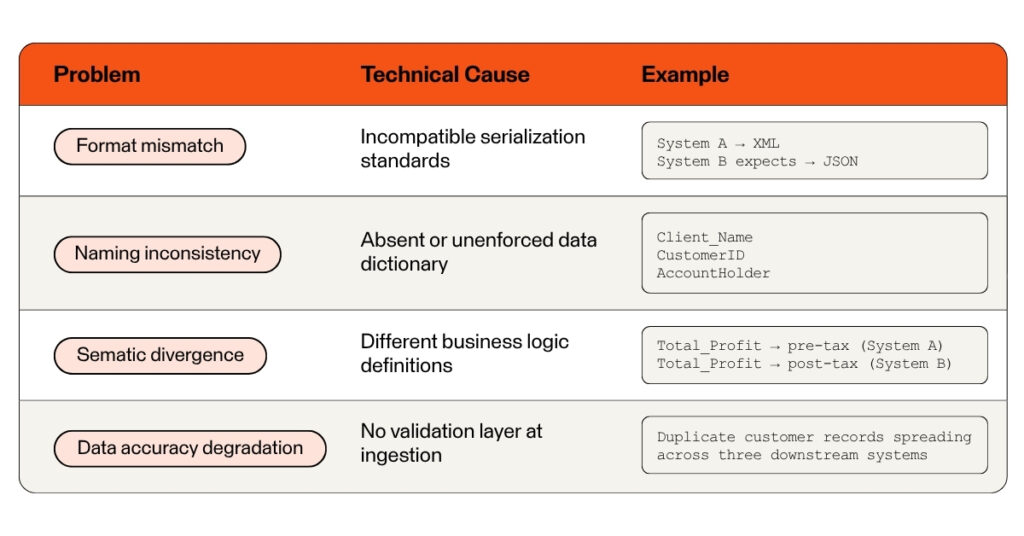
Even when two systems are technically connected, they may be speaking entirely different languages. This is the domain of schema mismatches and data quality issues, a category of interoperability challenge that is less visible than a broken pipeline but often more damaging in practice.
- Format differences, e.g. XML vs. JSON; storing dates as MM/DD/YYYY vs. Unix timestamps.
- Naming inconsistencies, e.g. storing the same information under Client_Name vs. CustomerID attributes.
- Semantic differences, e.g. the Total_Profit field is calculated differently across systems.
- Data accuracy problems, e.g. errors, missing values, and duplicate records in the source system propagate through every downstream system.
Each of these issues individually is manageable. Together, and at enterprise scale, they explain why data quality is widely cited as one of the top barriers to effective data interoperability.
API Complexity and Automation Gaps
Modern enterprises rely on APIs (application programming interfaces) as the connective tissue between their systems. In principle, APIs enable clean, standardized data exchange. In practice, they introduce a category of interoperability challenges that grows with the size and complexity of the organization.
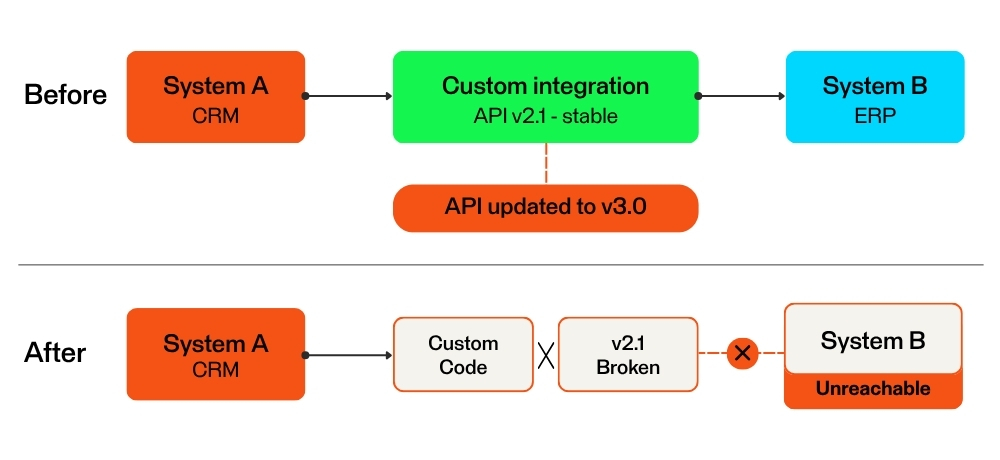
Point-to-point integrations break silently when API’s change – impact may not surface until downstream. Custom code must be manually identified, diagnosed, and patched before data flow can resume.
- Fragile point-to-point connections: Custom-coded integrations can break when a connected system changes.
- API versioning: External API updates can disrupt a data flow and break business processes.
- The manual process fallback: Employees may export data to spreadsheets, email them to colleagues, and re-enter information by hand. But manual processes are slow, error-prone, and impossible to audit reliably.
- Lack of centralized monitoring: Without a unified integration management layer, it’s difficult to check the health of all active data connections. A failed transfer might not be discovered until the impact has already propagated.
The combination of fragile integrations, unpredictable API changes, manual workarounds, and limited visibility creates an operational environment where interoperability is constantly at risk of degrading, even when it appears to be functioning.
Security, Governance, and Data Privacy Barriers
Data that flows freely between systems is difficult to protect. This is the central tension in the fourth major domain of interoperability challenges, and it has grown significantly more complex as regulatory environments have tightened and enterprise architectures have become more distributed.
- Accessibility versus security: Encryption, tokenization, and access controls must be applied and enforced at every node in the data flow. Security policies must be consistent across cloud platforms, on-premises databases, and third-party services.
- Privacy regulations: Frameworks such as GDPR, CCPA, and sector-specific regulations restrict how and where personal data can be processed and transferred. A data flow that is legal in one jurisdiction may be prohibited in another. Interoperability architectures must be designed to respect these boundaries.
- Data lineage tracking: Organizations need to be able to answer questions like: Where did this record originate? What transformations has it undergone? Who has accessed it, and when? Without robust lineage tracking, compliance audits and root-cause analysis after an incident become challenging.
- Permission management: User access rights in one system must be correctly reflected across all downstream systems. Permissions must be revoked or changed consistently and immediately across every system the data touches.
In most enterprises, these challenges overlap and compound over time. A poorly governed integration that was built quickly to solve a business problem three years ago may now be exposing sensitive data across systems that were never intended to share it.
Why Enterprise Data Interoperability Requires a Systemic Approach
Each of the challenges described above can be addressed individually. A schema mismatch can be resolved with a mapping rule. A broken API connection can be repaired. A missing audit log can be added. The problem with this kind of reactive, point-by-point remediation is that it does not scale, and it does not prevent the same categories of failure from recurring.
True interoperability requires treating data exchange as a standard capability of the organization, not as a series of individual projects. That means investing in three specific areas:
- Transformation: Organizations need tools and processes that can automatically translate data between different formats, naming conventions, and semantic definitions. This means establishing repeatable, auditable transformation logic that can be applied consistently as systems change. The FME Platform is one example of tooling built specifically to handle this kind of complex, multi-format data transformation at scale.
- Automation: Removing manual steps from data flows is a prerequisite for reliable interoperability. Manual processes introduce variability, create undocumented dependencies, and generate data quality issues that are difficult to trace. Automating data pipelines with proper error handling, retry logic, and alerting makes interoperability something that can be monitored and maintained, rather than something that has to be constantly fixed.
- Governance: Without clear rules for how data is secured, documented, and monitored as it moves between systems, interoperability becomes a liability rather than an asset. Governance includes data quality standards, access control policies, lineage tracking, and compliance controls. It also includes ownership: someone in the organization needs to be accountable for the health of each data flow, not just the systems at either end.
These three capabilities are mutually reinforcing. Transformation without governance produces fast-moving data that no one can trust. Automation without transformation moves data that cannot be understood. Governance without automation creates policies that are too slow and manual to enforce consistently.
Building a Foundation for Scalable Data
The challenges outlined in this article – data silos, schema mismatches, API fragility, and security constraints – are not new. What has changed is the scale at which they occur, the speed at which they need to be resolved, and the strategic consequences of leaving them unaddressed.
Organizations that build a genuine interoperability capability grounded in transformation, automation, and governance gain adaptability. When a new system needs to be onboarded, or a business process needs to change, or a regulation requires a new audit trail, the organization has the infrastructure to respond without rebuilding from scratch.
Connecting systems is a technical task, but ensuring they truly understand each other is a strategic necessity for any large organization that wants to make decisions based on accurate, trustworthy data.
Looking to understand how these challenges apply to your specific data ecosystem? Explore the FME Platform to see how enterprise data transformation and automation can support your interoperability goals.
Learn more:


