
AI Agentic Workflows: Tutorial & Best Practices
The emergence of large language models (LLMs) and their ability to reason has sparked a surge of interest in AI performing tasks and automating workflows.
The expression “agentic workflow” refers to systems with predefined code paths where LLMs call external tools and functions to carry out tasks. Meanwhile, the term “AI agent” has become associated with systems where LLMs make autonomous decisions to execute tasks based on dynamic workflows devised by LLMs.
This article explains the design patterns used in AI agents and agentic workflow systems and delves into the frameworks and best practices for implementing them. It also provides a simple implementation example of an agentic workflow using router and worker agents using LangGraph, before demonstrating how emerging no-code platforms can help create similar agentic workflows without programming.
Summary of key AI agentic workflows concepts
| Concept | Description |
|---|---|
| AI agent workflows | Agentic workflows are systems with predefined, structured, non-linear code paths in which LLMs, tools, and function calls are defined in a structured manner. They are different from AI agents, which are LLM-based autonomous systems that can dynamically plan, reason, and use appropriate tools from the environment to accomplish the task. |
| Different types of workflows | The most commonly used workflow design patterns are single-agent, routing, and handoff workflows. Parallel workflows, orchestrator workers, and evaluator-optimizer workflows are other options. |
| Building an AI Agent using agentic frameworks | Agentic frameworks like LangChain and LangGraph, intended for software developers, provide reusable building blocks to build Agentic workflows using popular programming languages. |
| Best practices while building AI agent workflows | Building Agentic Workflows can sometimes result in complex architectures, unnecessary tool calls, or instruction overload. Agentic workflow projects should start by deciding whether they are truly needed or if the requirements can be met using simpler technologies. |
| Using FME by Safe for building no-code data pipelines | Collating data from different sources with multiple schemas and different data types into standardised structured formats can be tedious to build from scratch for domain-specific use cases. FME (Feature Manipulation Engine) by Safe provides a no-code platform that helps build data pipelines that can combine multiple steps in a workflow fashion from various sources or cloud providers using AI agents as the orchestrator, which can later be connected with frameworks like LangGraph for further processing. |
Understanding AI agents and agentic workflows
Understanding the AI agent concept
We discussed how AI agents are different from agentic workflows. Before exploring agentic workflow patterns, let’s start by understanding the core concepts behind an AI agent.
The diagram below shows the most straightforward implementation of an AI Agent. It starts with input, which can be unstructured or structured data. It usually has few initial pre-processing or parsing steps, which are executed programmatically. The results are then passed to an instruction-based LLM, with a system prompt as the instruction and a user message as the context, along with model and client selection (such as OpenAI, Claude, or Deepseek) through an API call.
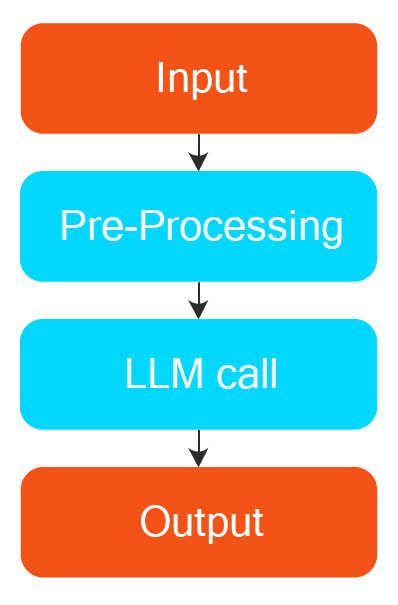
A personally identifiable information (PII) entity extractor is a simple real-world use case. First, you would collect all the required PDFs and place them in a folder—this would be our input part.
After this, the developer can create a simple PDF parser using Python libraries like PyMuPDF or Pdfplumber to extract the text inside the PDF and save it in a context variable. This covers the pre-processing step, assuming pre-built PDF loaders aren’t used.
Finally, a developer can pass the extracted text to the LLM (any local or hosted model like OpenAI) with a simple instruction prompt: “You are a PII entity extractor that can extract PII entities from the PDF text provided below. Read and understand the PDF carefully. Provide the output in a fixed JSON format. Do not add anything apart from the output format mentioned.”
Finally, the Output is received, parsed from the LLM response, and displayed in an interface or App.
Difference between AI agents and agentic workflows
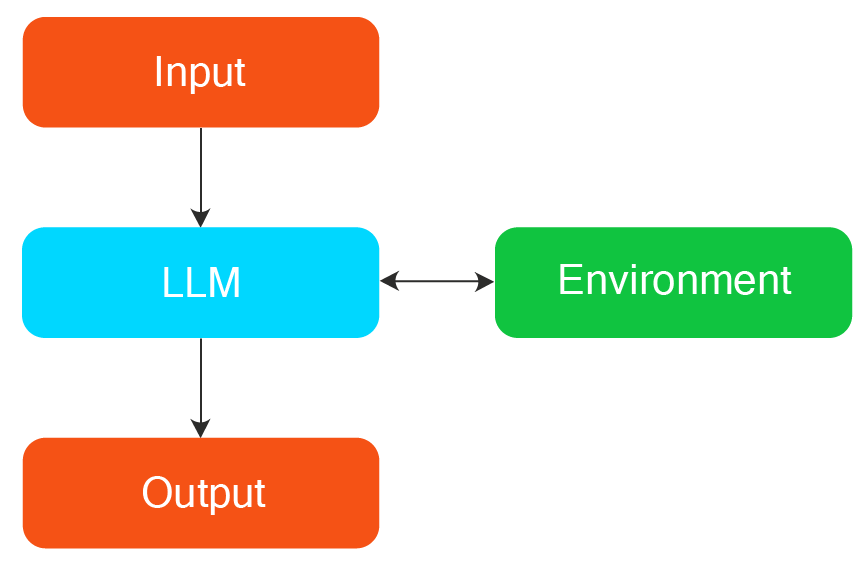
People often use AI agents and agentic workflows interchangeably; however, a key difference is that AI agents are goal-oriented. For example, if you want to build a website for your GitHub or something similar, you can pass that end goal on to an AI agent and provide access to all the necessary tools without implementing any prior steps or prompt chains (i.e., LLMs feeding each other). The agent will automatically plan, decide what steps to perform, and accomplish the task.
On the other hand, agentic workflows are predefined and work stepwise, and they cannot dynamically plan the route or the steps to perform if they do not have proper access or instructions.
Different types of agentic workflows
Workflows can be created with a single agent or multiple agents. Below, we describe the common AI agentic workflow design patterns.
Single Agent Workflow
For the first type of workflow, we have a predefined workflow capable of performing a single task, like extracting an entity, summarizing an email chain, and classifying the intent based on the email body. This simple pattern can also be used to build workflows where a single agent performs multiple tasks sequentially, like retrieving context from the vector store, classifying a context as Spam or ham, and writing a final email response to the vendor who requested an update.
This pattern is generally used for a single-step process in which the LLM is provided with a context as part of the prompt and asked to perform a task. It can also have multiple subtasks, such as classification tasks, and extract entities based on instructions provided in the same prompt.
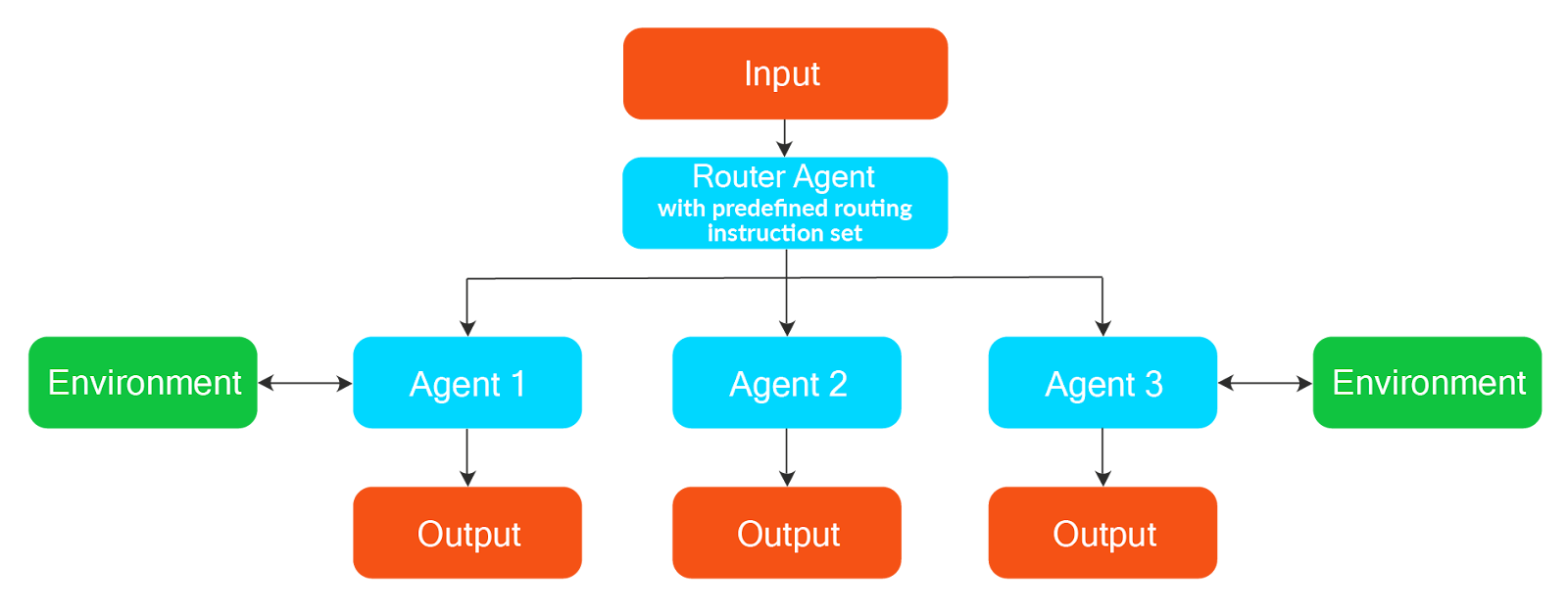
Routing and Handoff Workflows
Routing involves reading and understanding the input context and routing or delegating the task based on predefined rules to appropriate functions or agents to accomplish the task. Routing can be based on single-agent or multi-agent networks.
Handoffs are similar to routing and are generally used in multi-agent networks when one agent delegates a task to another. Handoffs are also used when the agent has completed the task from its side and hands the flow to a human for further evaluation or correction.
An example of a routing flow can be a customer service workflow in which the Routing Agent understands the incoming user query and, based on that, routes the request to an appropriate sub-agent depending on whether it relates to a finance query, a policy-related query, or an IT query. The sub-agent that received the delegated task provides the final output.
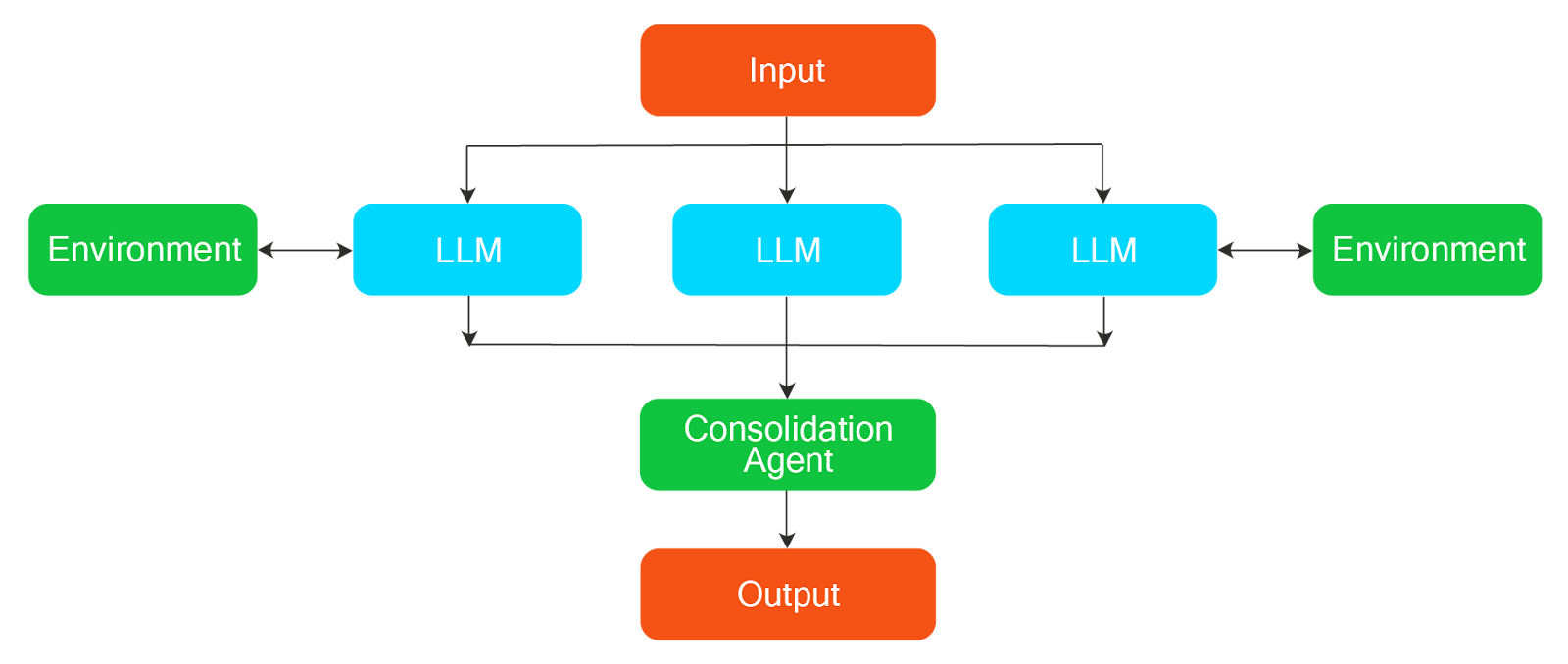
Parallelization Workflows
Workflows often involve several subtasks that are not dependent on the previous tasks. Executing independent tasks in parallel helps speed up the overall process. This is where parallelization workflows come in. Here, Agents work simultaneously on multiple subtasks independently and synthesize them into a single output function.
A real-world example of a parallelization workflow is a batch of research tasks to extract information from multiple research papers. One can create a parallelization workflow where all the agents are provided with different research papers in parallel, specific information from each of them is extracted, and, in the end, all the findings from different agents are collated to create a final report.
Orchestrator-worker Workflow
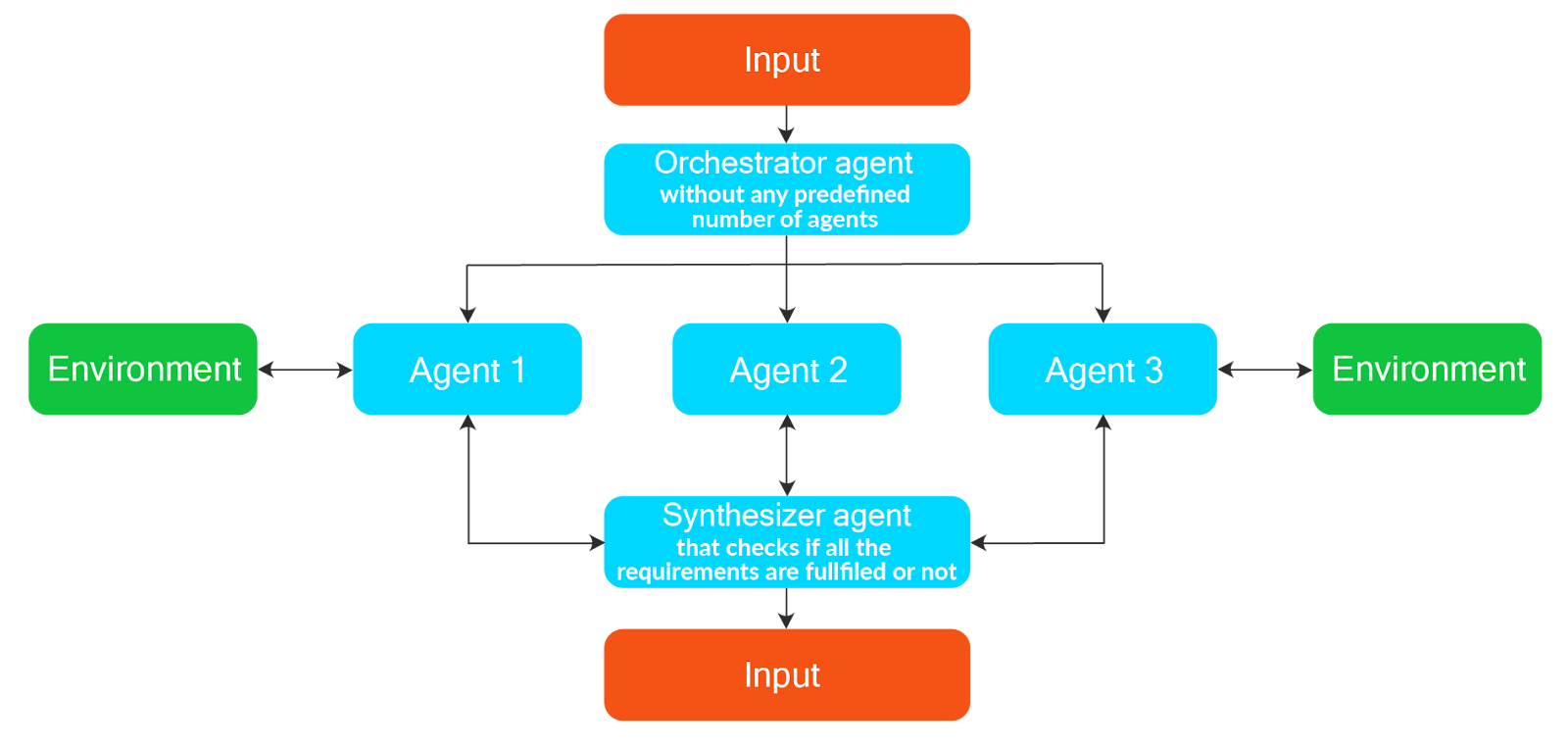
For workflows that involve dynamic decision-making, it may not be possible to define a flow logic while initializing a workflow. In such cases, an orchestrator agent may be responsible for creating a plan, determining a sequence of execution, and delegating tasks within an available pool of helper agents. This is called an orchestrator worker workflow. This is different from a parallelization workflow in that the number of agents or workers created in the orchestrator workflow is dynamic and depends on a decision made by the orchestrator. In the parallelization workflow pattern, the path is pre-defined.
A real-world example of a travel booking agent. Depending on the source and destination combination, the travel booking agent can explore flight, train, and rental car options, shortlist a few modes of transport, and delegate to sub-agents responsible for the shortlisted modes to check availability and fares. It can then collate information from sub-agents to create the final output.
Evaluator-Optimizer Workflow
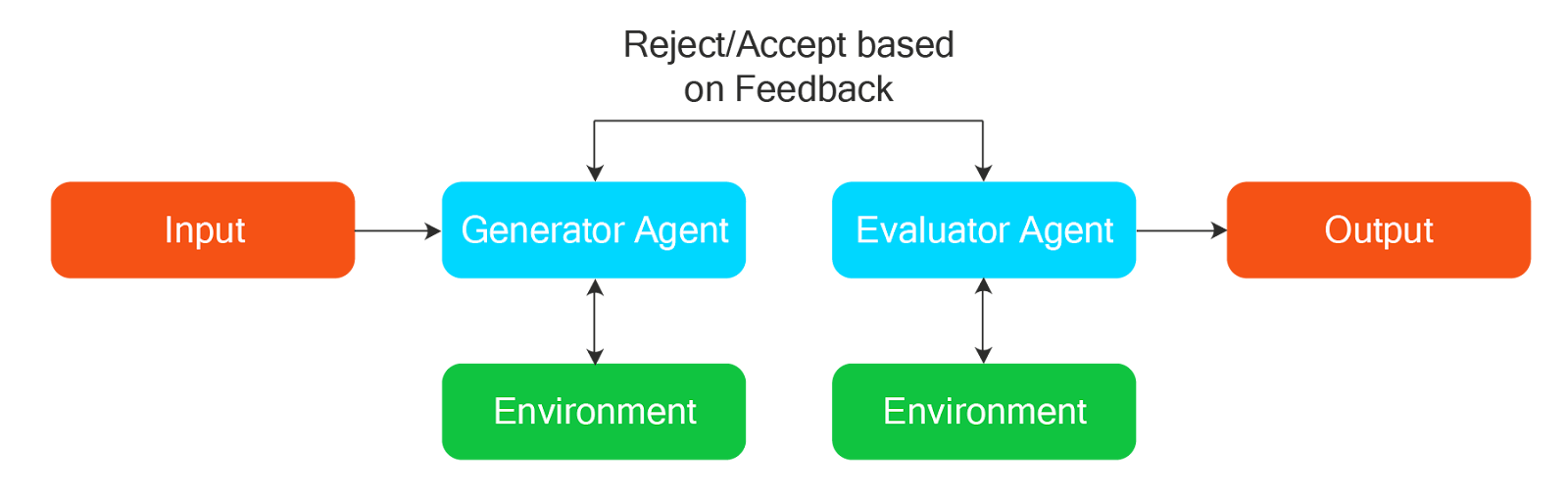
The creative nature of LLMs makes them suitable for tasks that involve the generation of text, images, ideas, or even working code. However, the same creativity can sometimes result in incorrect or less-than-ideal output. The evaluator-optimizer workflow attempts to address this problem. This is a multi-agent network type in which there are two agents—one that generates the output and the second one that evaluates the results based on previous feedback and business rules.
A simple real-world example of the Evaluator-Optimizer workflow is image generation based on prompts, where the generator agent generates the image, and the evaluator agent analyzes it to verify whether it is of the correct category.
Building a simple multi-agent workflow using LangGraph
Now that we are clear about the types of workflows, let us build a simple multi-agent workflow with three agents: a router agent and two worker agents.
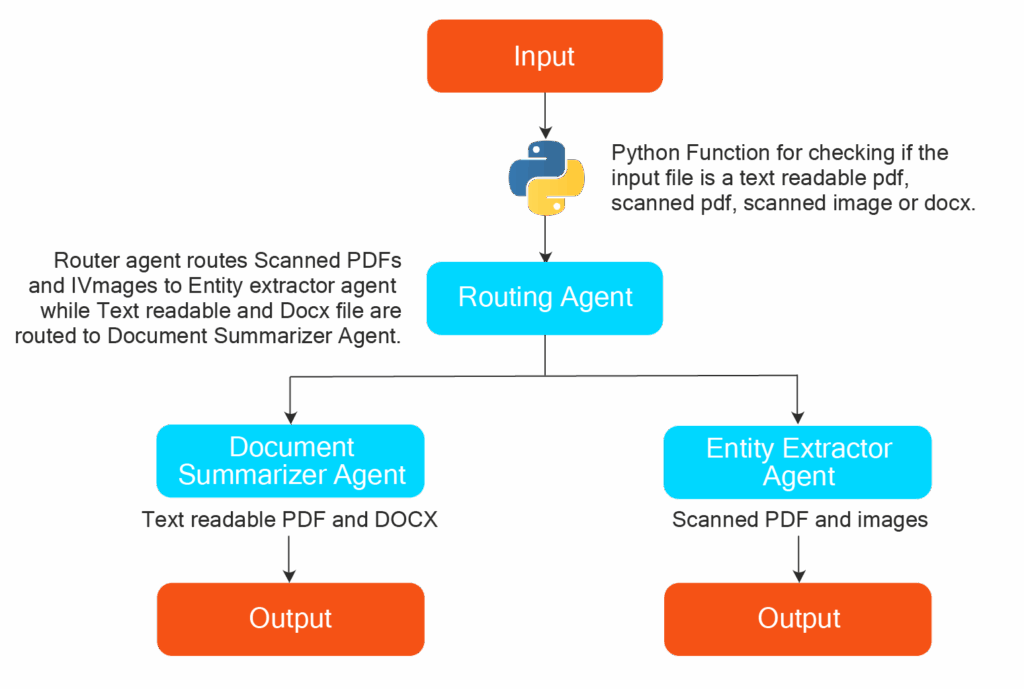
Our objective is to build a document processing agent that analyzes the document, identifies if it is a scanned PDF or a text-parseable PDF, and routes it to a vision-based optical character recognition (OCR) flow or a text processing flow. The OCR flow will use an Entity extractor agent to extract specific information, and the text parsing flow will use a document summarizer agent to generate summaries.
Let’s see how we can build it using LangGraph – an agent development framework for Python.
The code presented in this section includes code comments to explain the steps.
Step 1: As a first step, you will import all the modules and load our environment variable, to which we have added the OpenAI API key.
import os
import sys
import io
from typing import Dict, Any, TypedDict
import json
import os
from datetime import datetime
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import JsonOutputParser
from PIL import Image
import fitz # PyMuPDF library for PDF processingStep 2: Define variables to represent the state of the workflow.
# -----------------------------------------------------------------------------
# State Definition: Tracks document information throughout processing
# -----------------------------------------------------------------------------
class WorkflowState(TypedDict):
"""Represents the state of a document as it's processed through the workflow.
Attributes:
file_path: Path to the document being processed
file_type: Type of file (pdf, image, docx)
is_text_readable: Whether the document can be processed with direct text extraction
result: The final output after document processing
"""
file_path: str # Path to input document
file_type: str # Type of document (pdf, image, docx)
is_text_readable: bool # Whether text can be directly extracted
result: Dict[str, Any] # Processing results from specialized agentsStep 3: Define the utility functions to help us parse relevant file types.
def extract_text_from_pdf(file_path, is_text_readable):
"""Extract text from a PDF file using the appropriate method based on PDF type.
This function uses two different approaches:
1. For text-readable PDFs: Direct text extraction with PyPDF2
2. For scanned PDFs: OCR using GPT-4o Vision capabilities
Args:
file_path: Path to the PDF file
is_text_readable: Whether the PDF contains directly extractable text
Returns:
Extracted text content as a string
"""
# APPROACH 1: Text-readable PDF - Use standard text extraction
if is_text_readable:
import PyPDF2
text = ""
with open(file_path, 'rb') as file:
pdf_reader = PyPDF2.PdfReader(file)
# Extract text from each page and combine
for page in pdf_reader.pages:
text += page.extract_text()
return text
# APPROACH 2: Scanned PDF - Use vision-based OCR with GPT-4o
else:
try:
print("Processing scanned PDF with GPT-4o Vision...")
# Step 1: Convert the first page to an image
doc = fitz.open(file_path)
pix = doc[0].get_pixmap() # Render page to image
img_data = pix.tobytes("png") # Convert to PNG bytes
image = Image.open(io.BytesIO(img_data)) # Create PIL Image
# Step 2: Use GPT-4o's vision capabilities to extract text
return extract_text_with_gpt4o_vision(image)
except Exception as e:
print(f"Error extracting text from scanned PDF: {e}")
return f"Error processing scanned PDF: {str(e)}"
# -----------------------------------------------------------------------------
# DOCX Processing: Extract text from Word documents
# -----------------------------------------------------------------------------
def extract_text_from_docx(file_path):
"""Extract text from Microsoft Word DOCX files.
Uses the python-docx library to extract text from all paragraphs
in the document and combines them with line breaks.
Args:
file_path: Path to the DOCX file
Returns:
Extracted text content as a string
"""
import docx
doc = docx.Document(file_path)
# Extract text from all paragraphs and join with newlines
return "\n".join([para.text for para in doc.paragraphs])
def extract_text_with_gpt4o_vision(image):
"""Extract text from an image using GPT-4o vision capabilities.
Args:
image: PIL.Image object
Returns:
str: Extracted text from the image
"""
try:
# Initialize the GPT-4o model with vision capabilities
llm = ChatOpenAI(model="gpt-4o")
# Convert PIL image to base64 encoded string
buffered = io.BytesIO()
image.save(buffered, format="PNG")
img_str = base64.b64encode(buffered.getvalue()).decode()
# Prepare the message with the image content using the correct format
from langchain_core.messages import HumanMessage
message = HumanMessage(
content=[
{
"type": "text",
"text": "Extract all text visible in this image. Output only the text content, nothing else."
},
{
"type": "image_url",
"image_url": {"url": f"data:image/png;base64,{img_str}"}
}
]
)
# Get response from GPT-4o
response = llm.invoke([message])
# Extract the text content from the response
extracted_text = response.content
return extracted_text
except Exception as e:
print(f"Error in GPT-4o vision text extraction: {e}")
return f"Error in GPT-4o vision text extraction: {str(e)}"
The above code snippet uses PyMuPDF and python-docx to handle PDFs and docx files in the extract_text_from_pdf and extract_text_from_pdf functions.
The following section will use GPT-4o vision capabilities to handle image files and extract the text by passing the image.
# -----------------------------------------------------------------------------
# Image Processing: Extract text from image files
# -----------------------------------------------------------------------------
def check_file_type(file_path):
"""
Determine the type of file and whether it's text-readable or requires OCR.
Returns:
tuple: (file_type, is_text_readable)
"""
if not os.path.exists(file_path):
raise FileNotFoundError(f"File not found: {file_path}")
# Initialize mimetypes
mimetypes.init()
# Get file extension and determine MIME type
file_ext = os.path.splitext(file_path)[1].lower()
mime_type, _ = mimetypes.guess_type(file_path)
# Handle cases where mimetypes doesn't recognize the file
if not mime_type:
if file_ext == '.pdf':
mime_type = 'application/pdf'
elif file_ext == '.docx':
mime_type = 'application/vnd.openxmlformats-officedocument.wordprocessingml.document'
elif file_ext in ['.jpg', '.jpeg', '.png', '.bmp', '.tiff', '.gif']:
mime_type = f'image/{file_ext[1:]}'
print(f"Detected MIME type: {mime_type}")
# Image files
if mime_type and mime_type.startswith('image/'):
return "image", False
# PDF files
elif mime_type == 'application/pdf' or file_ext == '.pdf':
# Check if PDF is text-readable or scanned
return check_pdf_readability(file_path)
# DOCX files
elif mime_type == 'application/vnd.openxmlformats-officedocument.wordprocessingml.document' or file_ext == '.docx':
return "docx", True
else:
raise ValueError(f"Unsupported file type: {mime_type or file_ext}")
def extract_text_from_image(file_path):
"""Extract text from image files using GPT-4o's advanced vision capabilities.
This function leverages GPT-4o's multimodal abilities to perform OCR on images,
which provides more accurate text extraction than traditional OCR tools.
Args:
file_path: Path to the image file
Returns:
Extracted text content as a string
"""
try:
# Load the image using PIL
image = Image.open(file_path)
# Use GPT-4o vision model to extract text
return extract_text_with_gpt4o_vision(image)
except Exception as e:
print(f"Error extracting text from image: {e}")
return f"Error processing image: {str(e)}"
Step 4: You will now create our Entity Extractor Agent to extract entities for Scanned PDF or Image files.
class EntityExtractorAgent:
"""Agent specialized for extracting structured information from scanned documents/images."""
def __init__(self, llm):
"""Initialize the agent with a language model.
Args:
llm: Language model for entity extraction
"""
self.llm = llm
# Define the prompt that guides the model to extract specific entity types
self.prompt = ChatPromptTemplate.from_template("""
You are an expert entity extraction agent.
Your task is to extract key entities from the following text that was obtained from a scanned document or image.
Please extract the following entities:
1. Names of people
2. Organizations
3. Dates
4. Locations
5. Key numerical values (amounts, percentages, etc.)
Format your response as a JSON object with these categories as keys.
Text content:
{text_content}
""")
def process(self, text_content):
"""Process extracted text to identify and categorize entities.
Args:
text_content: The text extracted from the document
Returns:
Structured dictionary of extracted entities by category
"""
print("Entity Extractor Agent: Processing text content...")
# Invoke the processing chain with the extracted text
result = self.chain.invoke({"text_content": text_content})
return result
Step 5: The next step is to create a document summarizer Agent to summarize documents for Text-readable files.
class DocumentSummarizerAgent:
"""Agent specialized for creating structured summaries of text-readable documents."""
def __init__(self, llm):
"""Initialize the agent with a language model.
Args:
llm: Language model for document summarization
"""
self.llm = llm
# Define the prompt that guides the model to create specific summary components
self.prompt = ChatPromptTemplate.from_template("""
You are an expert document summarization agent.
Your task is to create a comprehensive summary of the following document.
Please provide:
1. A concise executive summary (2-3 sentences)
2. Key points (bullet points)
3. Main topics covered
4. Important conclusions or recommendations
Format your response as a JSON object with these categories as keys.
Document content:
{text_content}
""")
# Configure JSON output parser to ensure structured responses
self.output_parser = JsonOutputParser()
# Create the LangChain processing pipeline: prompt → LLM → JSON parser
self.chain = self.prompt | self.llm | self.output_parser
def process(self, text_content):
"""Process document text to create a structured summary.
Args:
text_content: The text extracted from the document
Returns:
Structured dictionary with summary components
"""
print("Document Summarizer Agent: Processing text content...")
# Invoke the processing chain with the extracted text
result = self.chain.invoke({"text_content": text_content})
return result
Step 6: You will now create the routing agent that can first take the input file, figure out its type, determine whether it is text-readable or scanned, and, based on that, route it to the relevant agent.
# Router function
def route_document(file_path):
"""Route the document to the appropriate agent based on file type"""
print(f"\nRouting document: {file_path}")
# Initialize state
state = WorkflowState(
file_path=file_path,
file_type="",
is_text_readable=False,
result={}
)
# Check file type
file_type, is_text_readable = check_file_type(file_path)
state["file_type"] = file_type
state["is_text_readable"] = is_text_readable
print(f"Router Agent: File type detected: {file_type}, Text readable: {is_text_readable}")
# Initialize LLM
llm = ChatOpenAI(model="gpt-4o")
# Extract text based on file type
if file_type == "pdf":
text_content = extract_text_from_pdf(file_path, is_text_readable)
elif file_type == "image":
text_content = extract_text_from_image(file_path)
elif file_type == "docx":
text_content = extract_text_from_docx(file_path)
else:
return {"error": f"Unsupported file type: {file_type}"}
# Preview the extracted text
print("\nExtracted text preview:")
print(text_content[:500] + "..." if len(text_content) > 500 else text_content)
# Use OpenAI LLM to decide which agent to route to
print("\nAsking Router LLM to determine the best agent for processing...")
# Create a router prompt for the LLM to decide on the appropriate agent
router_prompt = ChatPromptTemplate.from_template(
"""
You are a document routing agent that needs to decide which specialized agent
should process a document based on its content and format.
Document Type: {file_type}
Is Text Readable: {is_text_readable}
Document Content Preview:
{text_preview}
Based on this information, determine which agent should process this document:
- Entity Extractor Agent: Specialized in extracting structured entities from scanned documents,
images, or non-text-readable documents. Good for processing forms, invoices, receipts, etc.
- Document Summarizer Agent: Specialized in summarizing and extracting key information from
text-readable documents like reports, articles, or regular PDFs with extractable text.
Output ONLY 'entity_extractor' or 'document_summarizer' based on your decision.
"""
)
# Execute the router LLM call
text_preview = text_content[:1000] + "..." if len(text_content) > 1000 else text_content
router_input = {
"file_type": file_type,
"is_text_readable": is_text_readable,
"text_preview": text_preview
}
router_response = llm.invoke(router_prompt.format_messages(**router_input))
routing_decision = router_response.content.strip().lower()
# Apply the LLM's routing decision
if "entity_extractor" in routing_decision:
print("\nLLM Routing Decision: Entity Extractor Agent")
entity_extractor = EntityExtractorAgent(llm)
result = entity_extractor.process(text_content)
state["result"] = {
"source": "entity_extractor",
"extracted_entities": result
}
elif "document_summarizer" in routing_decision:
print("\nLLM Routing Decision: Document Summarizer Agent")
document_summarizer = DocumentSummarizerAgent(llm)
result = document_summarizer.process(text_content)
state["result"] = {
"source": "document_summarizer",
"document_summary": result
}
else:
# Fallback in case the LLM doesn't return a clear decision
print(f"\nUnclear routing decision: '{routing_decision}', using default routing logic")
if file_type == "image" or (file_type == "pdf" and not is_text_readable):
print("Defaulting to Entity Extractor Agent...")
entity_extractor = EntityExtractorAgent(llm)
result = entity_extractor.process(text_content)
state["result"] = {
"source": "entity_extractor",
"extracted_entities": result
}
else:
print("Defaulting to Document Summarizer Agent...")
document_summarizer = DocumentSummarizerAgent(llm)
result = document_summarizer.process(text_content)
state["result"] = {
"source": "document_summarizer",
"document_summary": result
}
return state
Step 7: Finally, you can save the outputs in JSON format, with the filename and timestamp in the final name.
def save_output_to_file(result):
"""Save processing results to organized output files.
This function creates a structured output directory with:
1. Agent-specific results based on which agent processed the document
2. Complete results with all workflow data
Args:
result: The final state dictionary with processing results
Returns:
Path to the output directory
"""
# Create output directory with timestamp
output_dir = os.path.join(os.path.dirname(os.path.abspath(__file__)), "outputs")
os.makedirs(output_dir, exist_ok=True)
# Generate a timestamp for unique filenames
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
# STEP 1: Save agent-specific results based on which agent processed the document
# For documents processed by the Entity Extractor
if result["result"].get("source") == "entity_extractor":
output_file = os.path.join(output_dir, f"entity_extraction_results_{timestamp}.json")
with open(output_file, "w") as f:
json.dump(result["result"]["extracted_entities"], f, indent=4)
print(f"Entity extraction results saved to: {output_file}")
# For documents processed by the Document Summarizer
elif result["result"].get("source") == "document_summarizer":
output_file = os.path.join(output_dir, f"document_summary_results_{timestamp}.json")
with open(output_file, "w") as f:
json.dump(result["result"]["document_summary"], f, indent=4)
print(f"Document summary results saved to: {output_file}")
# STEP 2: Save the complete workflow results
full_results_file = os.path.join(output_dir, f"full_results_{timestamp}.json")
with open(full_results_file, "w") as f:
# Convert any non-serializable objects to strings (like Path objects)
json_result = {k: str(v) if not isinstance(v, (dict, list, str, int, float, bool, type(None))) else v
for k, v in result.items()}
json.dump(json_result, f, indent=4)
print(f"Complete results saved to: {full_results_file}")
return output_dir
Step 8: Create a main function to stitch everything together and run the code.
# -----------------------------------------------------------------------------
# Main Application: Entry point for document processing
# -----------------------------------------------------------------------------
def main():
"""Main function to run the document processing workflow.
This function:
1. Gets the document path from the command line or uses a default
2. Processes the document through the router workflow
3. Saves all outputs to organized files
"""
# STEP 1: Get the document to process (from command line or default)
if len(sys.argv) > 1:
file_path = sys.argv[1]
else:
# Default to a sample document if none provided
file_path = "C:\\Users\\sample_invoice_scanned.pdf"
print(f"Using default file path: {file_path}")
# STEP 2: Process the document
# Process the document using our routing system
result = route_document(file_path)
# STEP 3: Display the processing results
print("\n--- Processing Result ---")
print(result) # Show the final state with processing results
# STEP 4: Save all outputs to organized files
output_dir = save_output_to_file(result)
# Entry point for running the application
if __name__ == "__main__":
try:
main()
finally:
# Ensure logs are saved even if there's an error
# logger.save_logs()
pass
Step 9: Let’s see how it works if we pass this with an image file.

Step 10: Here is how the output logs look after running this image through our Multi-agent. The final JSON looks as below, and it has captured the entities from the Image.
{
"Names of people": [
"Jack Reilly",
"Jim Daley"
],
"Organizations": [
"Shook, Hardy & Bacon L.L.P.",
"Federal Express",
"Legal Edge"
],
"Dates": [
"January 31, 1997",
"February 5"
],
"Locations": [
"One Kansas City Place",
"1200 Main Street",
"Kansas City, Missouri 64105-2118"
],
"Key numerical values": [
{
"telephone": "(816) 474-6550",
"facsimile": "(816) 421-5547",
"telecopy no.": "212/545-3297",
"pages transmitted": 3,
"client matter no.": "LORI:45048",
"operator extension": 200,
"other number": 83772145
}
]
}
Our implementation took tens of lines of code and required a deep understanding of LangGraph, the agentic framework that we used to implement this.
If you don’t have such engineering resources, exploring no-code agentic platforms like FME is a practical alternative. FME can build complex domain-specific agentic workflows in a no-code environment with access to all cloud platforms like Azure, GCP, and AWS and support for all LLM models. It can also help professionals with low-code experience build agentic workflows for their existing data pipelines. We will briefly cover this in the next section.
Leveraging FME by Safe to build data pipelines and agentic systems
FME (Feature Mapping Engine) by Safe is a no-code, all-data, any-platform application where users can build data pipelines using AI agents to ingest structured or unstructured data from multiple schemas and data types into standardized formats.
It also helps to build automated workflows using AI agents hosted on leading cloud platforms such as Azure, GCP, and AWS.
FME has two solutions for building data workflows – FME Form and FME Flow.
FME Form—FME provides a no-code environment for users to build automated data workflows. It offers options to add multiple agents and seamlessly connect outputs from one block to another.
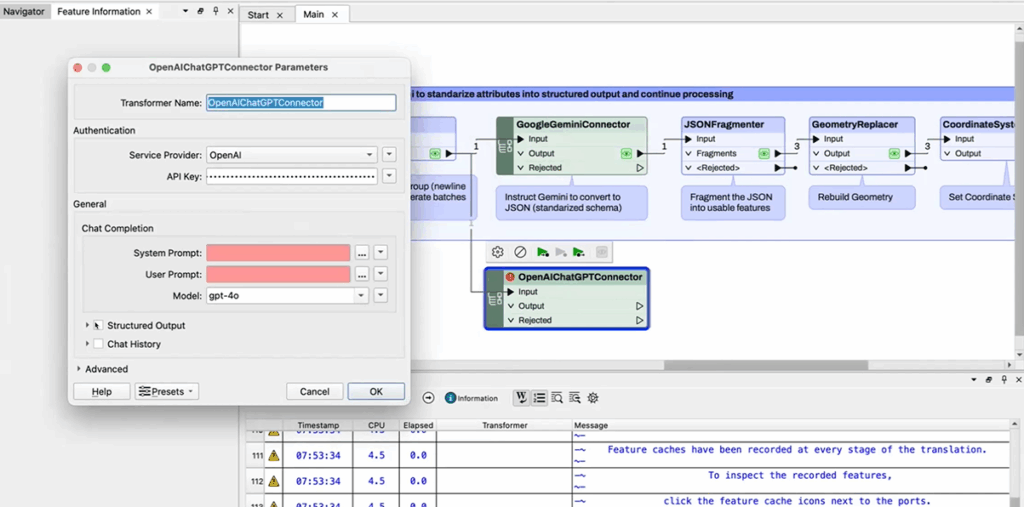
FME Flow—This area of functionality allows users to deploy their completed workflows and bring the solution live. It also handles CI/CD of data workflows or applications.
For our Router agent workflow, which we built using LangGraph, the initial step of converting unstructured data to a standardized structured format can be done easily through the FME platform. FME can handle all the heavy lifting in creating the data pipelines, which LangGraph can use as input, thereby greatly reducing the required coding.
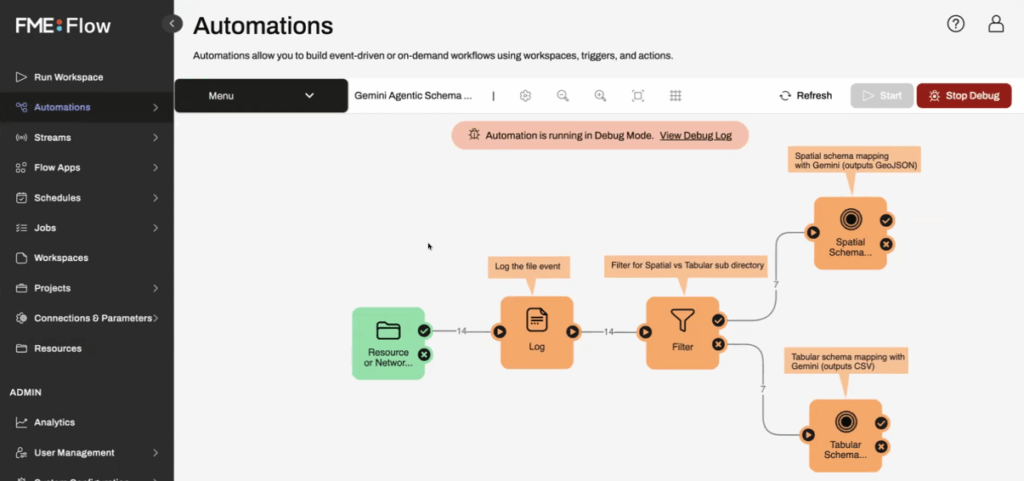
Best practices for building AI agent workflows
Getting LLM-based prototypes working has become easier than ever, thanks to readily available code snippets and ChatGPT-like assistants. That said, taking such applications to production is a herculean task that requires several iterations. The following section details some best practices to avoid common mistakes and achieve project success.
Keep the application workflow as simple as possible to avoid unnecessary LLM calls
Take the time to create a rough flow or architecture of the use case when building a workflow, whether for a domain-specific problem statement or a general one. Then, identify the steps where automation is possible. After that, decide if an automation opportunity requires an LLM or can be programmatically handled through code. Adding unnecessary LLM calls for fixed or code-based tasks can lead to additional cost spikes and less predictable outcomes. LLMs are best for tasks where the outputs can’t follow rules or guidelines, but instead depend on the context provided by the user. For example, consider an automobile subrogation from a car insurance application, where the agent must interpret the claim notes written by the claim adjuster. Such problems cannot be handled programmatically based on keywords or similarity. LLMs would help interpret, reason, and decide the next steps based on the scenario.
Log all the steps to enhance transparency, or use tools for monitoring and logging
Debugging the workflows to isolate the mistakes is necessary but tedious. It requires tracking the prompts and output pairs. Because LLM results are inconsistent, monitoring the outputs is a mandatory check for applications intended for commercial use. Tools like LangSmith and Patronus help monitor the relevance, cost, and latency of LLM responses. If you are building data pipelines for extracting structured data from unstructured data with multiple schemas and data types, then you can also explore FME Flow by Safe, which offers monitoring and tracking of all your data workflows.
If you are a developer and want to explore open-source tools, then a tool like LangTrace can help you with observability and evaluation for building agentic workflows.
Create well-defined instruction sets for LLMs
Creating well-defined instruction sets for LLMs is one of the foundational steps on which to spend most of your time. Defining the output well helps build a system, prompts, or an instruction set.
When building domain-specific prompts or instructions, it is generally recommended to explain business entities and the overall flow of the business so that the LLM knows what to focus on and what not to. A good practice to understand why LLM has made a certain decision is to ask for a 2-3 liner explanation along with the expected output; this generally helps in the prompt tuning process.
For consistent output, it is also recommended to include sentences like “You are prohibited or not allowed to do things” in your prompt to clarify. Setting the LLM temperature parameter to 0 and the seed parameter to some random value also helps the LLM to be more consistent and deterministic. In an LLM, the seed parameter is an integer that initializes the random number generator, ensuring that the model produces the same output for a given input and set of parameters across different runs, making the generation process deterministic.
Create guardrails and hallucination detection layers
It is generally advised to create guardrail layers and hallucination detection prompts inside your workflows to identify if the user is trying to manipulate, ask irrelevant questions, or use prompt injection techniques.
Guardrails and hallucination layers are also essential for detecting if the LLM or AI agents have made a mistake in the output generation, so that it can be detected quickly and sent for a re-run. They can also highlight or trigger a human-in-the-loop review for scenarios where a particular LLM call is taking longer to run than expected, thus giving hints on possible injections or manipulations, or simply pointing to a load balancing issue from cloud servers. Including these layers in your agentic workflows helps you get proper sleep during go-live scenarios.
Guardrail layers can sometimes include human-in-the-loop functionality, which stops the workflow and waits for human approval before executing crucial steps.
Define well the calls made to tools and functions
Function and tool calling capabilities are standard in agentic workflows. For example, LLMs aren’t good at mathematical calculations or analyzing large amounts of data stored in a database. In such cases, calling a tool or function can give the LLM access to essential libraries like Python REPL or a database to query using text-to-SQL techniques. But this can sometimes lead to unnecessary API calls, hung calls, or erroneous responses, leading the workflow to break or drift away from the intended goal. Thus, implementing and testing tool and function calls is a good practice to avoid unnecessary costs and latency issues.
Systematically evaluate the choice between agents and agentic workflows
Delegating decisions to an AI agent instead of predefining workflows may seem most efficient; however, LLMs aren’t deterministic. In most cases, an agentic workflow will provide better reliability and reproducibility than an AI agent. Consider the following:
- Agents generally increase the latency due to thinking, intermediate reminders of context, and additional tool-calling context. Agentic workflows offer less latency because of their hard-coded nature.
- Agents are harder to control and sometimes give inconsistent outputs in complex workflows.
- Agents are generally more expensive due to the cost incurred by the additional tokens.
- If your use case can be solved using pre-defined steps, use workflows.
Last thoughts
AI agents and agentic workflows are excellent solutions for streamlining business and consumer applications; however, conventional workflow automation techniques not involving LLMs should not be overlooked, as they may provide a more predictable and simpler solution.
When choosing a platform to implement an agentic workflow, consider the platform’s support for different types of AI models and the data pipeline functionality required to transform and feed data into the workflow. The other key consideration is whether the project has a budget to hire a team of developers to implement the workflows using tools like LangGraph.
No-code platforms like FME by Safe offer a cost-efficient alternative for enterprises looking to implement AI agentic workflows rapidly while empowering a broader cross-section of their organization, including business analysts, data scientists, and managers ready to contribute but unfamiliar with programming languages.
Continue reading this series
AI Agent Architecture: Tutorial & Examples
Learn the key components and architectural concepts behind AI agents, including LLMs, memory, functions, and routing, as well as best practices for implementation.
AI Agentic Workflows: Tutorial & Best Practices
Learn about the key design patterns for building AI agents and agentic workflows, and the best practices for building them using code-based frameworks and no-code platforms.
AI Agent Routing: Tutorial & Examples
Learn about the crucial role of AI agent routing in designing a scalable, extensible, and cost-effective AI system using various design patterns and best practices.
AI Agent Development: Tutorial & Best Practices
Learn about the development and significance of AI agents, using large language models to steer autonomous systems towards specific goals.
AI Agent Platform: Tutorial & Must-Have Features
Learn how AI agents, powered by LLMs, can perform tasks independently and how to choose the right platform for your needs.
AI Agent Use Cases
Learn the basics of implementing AI agents with agentic frameworks and how they revolutionize industries through autonomous decision-making and intelligent systems.
AI Agent Tools: Tutorial & Example
Learn about the capabilities and best practices for implementing tool-calling AI agents, including a Python-based LangGraph example and leveraging FME by Safe for no-code solutions.
AI Agent Examples
Learn about the core architecture and functionality of AI agents, including their key components and real-world examples, to understand how they can complete tasks autonomously.
No Code AI Agent Builder
Learn the benefits and limitations of no-code AI agent builders and how they democratize AI adoption for businesses, as well as the key components and features of these platforms.
Multi-Agent Systems: Implementation Best Practices
Learn about multi-agent systems and how they improve upon single-agent workflows in handling complex tasks with specialised roles, communication, coordination, and orchestration.
Langgraph Alternatives: The Top 6 Choices
Learn about LangGraph, a powerful yet complex orchestration framework for building intelligent systems, and its limitations, alternatives, and selection criteria.
Agentic AI vs Generative AI
Learn the differences between generative AI and agentic AI and how to choose the right AI paradigm for your needs.