
Analyzing job statistics in FME server

Knowing how to make the best of the resources at hand is a challenge seen nearly everywhere.
Each morning I sit down, log on for the workday, and look ahead at the meetings and the outstanding items I have to do. One way to look at the relationship between myself and the work is: I’m the resource that needs to complete all these tasks. Which means, I need to take an inventory and prioritize. And that works fine—I can write down my top goal for the day and chip away at them.
But, imagine I’m told at the last minute that my next task isn’t important, so I can take it off the to-do list. And then suddenly, maybe the due date on writing this blog was moved up. All right, maybe I can handle that sort of change. However, what happens when you have multiple people (or resources) to manage and those people (or resources) are also all impacted by these changes? What if priorities constantly change?
This isn’t so much a “what if” as it is a reality. Things do change, and they can change fast. This is especially true when it comes to prioritizing data workflows in FME Server. Rather than people, your resources are FME Engines, and those tasks are jobs that need processing.
This is why we’ve introduced ‘Job statistics’ in FME Server and a new way to manage the distribution of FME Engines and the jobs that need to be processed. And guess what? It scales and only needs to be configured once.
Job Statistics in FME Server
Let’s take a look at exactly what I’m talking about. What are the new Job statistics?
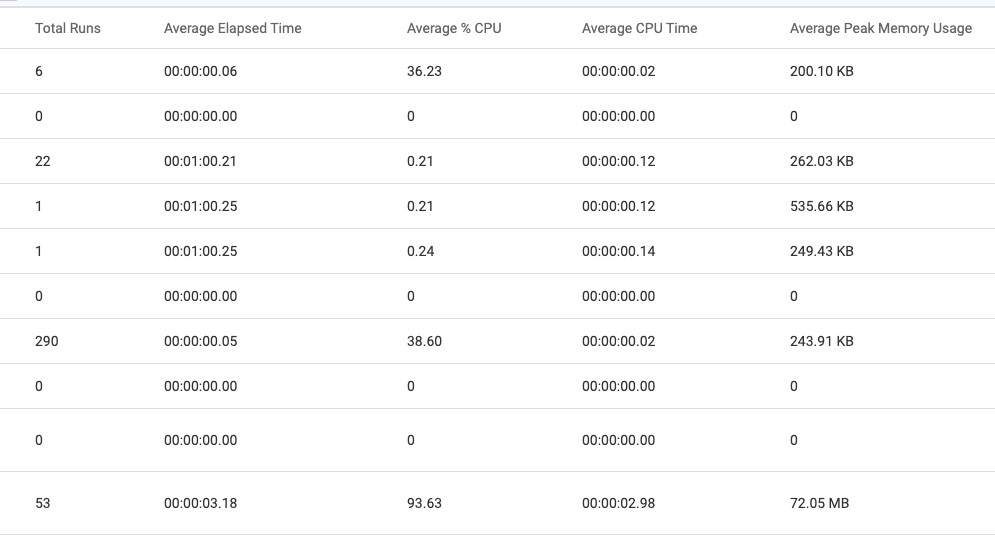
Job statistics in FME Server contain information on Job processing time, CPU usage, and memory usage to better understand their FME Server activity and how their Jobs are performing.
Job statistics can be found in Jobs > Completed by customizing the columns. They can also be viewed when looking at individual Workspaces. These are the new statistics that are available:
- Total Runs: The total number of times FME Server has run a Job.
- Average Elapsed Time: Total processing time for a Job (Note: “Elapsed Time” was previously called “Duration”). This is useful as this gives us the ability to know what the “expected” elapsed time would be.
- Average % CPU: The actual time spent processing, excluding any network activity. (Average CPU Time/Average Elapsed Time)
- Average CPU Time: The average CPU time across all invocations.
- Average Peak Memory Usage: The average amount of memory a Job required while it was processing.
Now that you have this information, your next question probably is, “What do I do now?”.
Here are some example of actions you can take in response:
- When the Average Peak Memory Usage is high—especially over 1 GB—then there might be inefficiencies within the workspace itself. These workspaces will also be at risk to compete for resources when running Jobs in parallel.
- If you see that the Average CPU Time is low, then that’s a great signal these Jobs are primed to take advantage of Dynamic Engines (and their CPU time payment model).
- For Jobs that never seem to make an increment on Total Runs, you might be able to clean up or remove them from FME Server to keep things organized—of course, make sure you check with the workspace owner first!
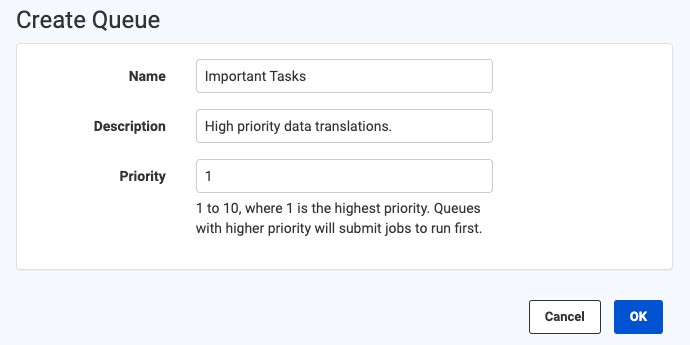
Queue Control: Using Job Stats to Prioritize & Re-Prioritize
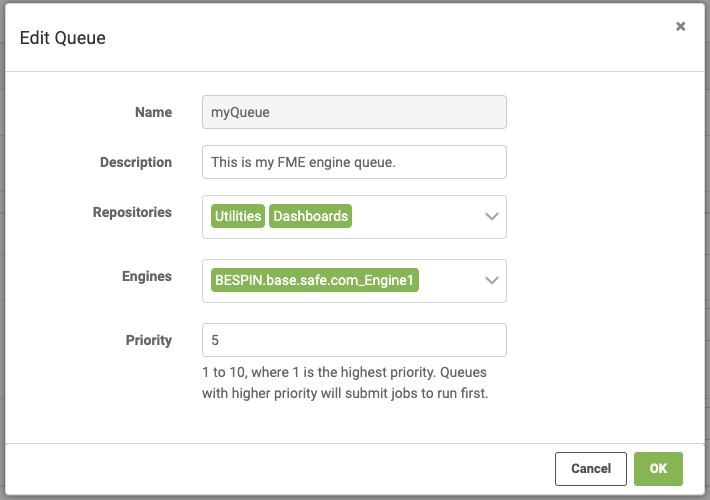
Previously, an FME Server administrator would create a queue and then only have the ability to assign repositories (a collection of workspaces) to be processed by 1 or more FME Engines. Once that was setup it could be changed, sure, but often you only would change it by the number of FME Engines allocated or what repositories if you ran into bottlenecks or other problems. It was a great solution, but it still required a lot of monitoring by the administrators.
The workflow looked like this:
 Now, with the addition of Job statistics, we’ve also added new Queue Control features: Job Routing and Engine Assignment Rules.
Now, with the addition of Job statistics, we’ve also added new Queue Control features: Job Routing and Engine Assignment Rules.
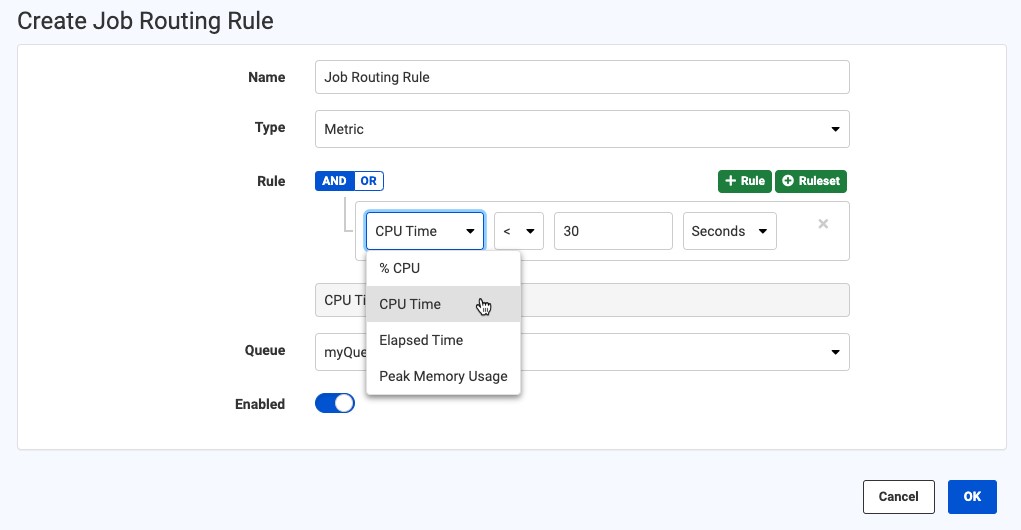
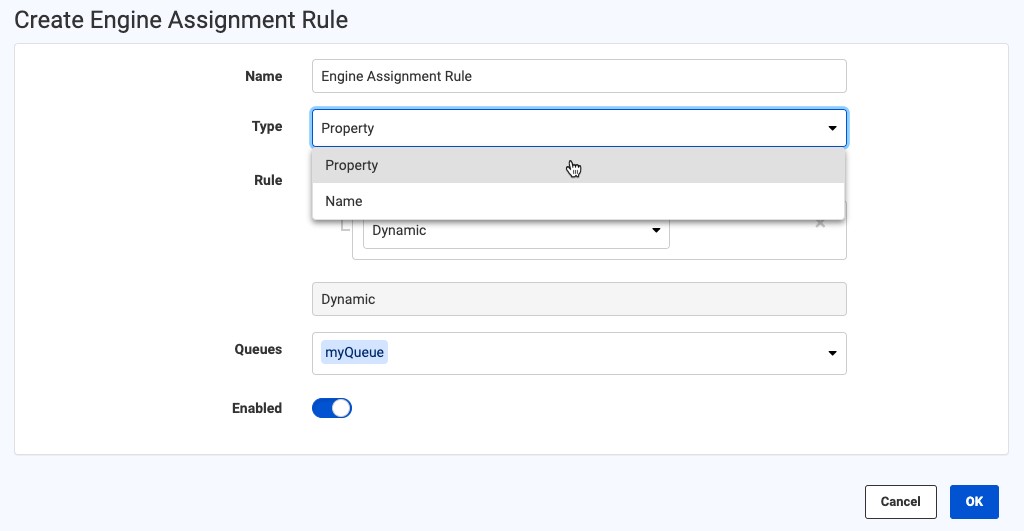
And no, I didn’t forget about assigning FME Engines, did you? Let’s look at Engine Assignment Rules:
There is still the option to assign specific engines to specific FME Server queues, but there is now the notion of FME engine “Properties”.

Currently there are only a handful of properties available including FME engine type (Standard or Dynamic) and the operating system (for deployments with mixed Windows or Linux engines). There will be more coming in time to enable more flexibility.
If only I could have FME Server managing my day-to-day tasks like this!
Now that I’ve told you all about Job statistics and the new queue control option in FME Server, I bet that you are wondering when should I start using it? The answer is simple: if you have FME Server 2021 or newer, start today!
There are also a few things that will make your configuration more effective:
- Jobs need to run multiple times before they have reliable statistics
- If the input parameters or source data changes significantly between runs then the outliers might not be captured by the rules you create
- The ordering of rules matters: the Engine Assignment and Job Routing rules are evaluated in the order they are listed (you can think of it like if-else statements)
- Use ranges where possible instead of absolute values
- Queues can themselves be prioritized—this is useful if you have Engine Assignment Rules that place an FME engine in multiple queues
- Start simple and expand from there
Paving the Way for Auto-Scaling
You made it through all of that information and I never mentioned auto-scaling? For anyone that has tuned into our webinars, you might know that one of the long-term visions we have for FME Server is to give you the ability to configure your FME Engines to auto-scale in response to demand on your deployment.
What is auto-scaling in this context? Well, it’s all about those FME Engines. While there are some users out there who can provide resources (CPU, memory) for FME Engines around the clock, it’s not the most ideal manual task. With auto-scaling, there’s no need for manual resource management. Instead, FME will add and remove engines for you automatically to ensure your workflows keep running efficiently.
You might be thinking, “But, more engines means more money!” That’s not the case. We have already introduced Dynamic Engines to balance the financial side of that equation. Instead of paying for engines directly, you only pay for CPU time. This combined with the new Job statistics will make it much easier for you to budget and know what to expect.
As for the management side? That’s what we are working on right now. The Job Routing and Engine Assignment Rules will be the foundation for how we address auto-scaling engines for FME Server. It has introduced new ways to manage the distribution of engines across FME Server Queues. To get this far, we have started to introduce new properties and new metrics that we can use as criteria.
The next steps will be leveraging this information to dictate how many engines are running. And yes, you will have the ability to scale either regular or Dynamic Engines. I can tell you that it’s not trivial to work out this problem so I expect that we will continue to see these incremental improvements that allow us get one step closer with each release.
If auto-scaling your FME Engines is something that interests you, then please get in touch with us. We would love to learn about your environment, how you have deployed FME Server, and what requirements you would need in a world of auto-scaling FME Engines. Feel free to post a question to the FME Community or comment below!


