Creating a dynamic workflow with FME

How can you create a dynamic workflow within the FME platform? Dynamic workflows are a key concept in FME that can save you a lot of time and effort when authoring workspaces. This is when the feature types are flexible and can accept any schema or data model, instead of a typical workspace where the feature types are explicitly tied to a name, a specific set of attributes, and specific geometry types. Think of it as a schema-independent way of creating a workspace.

Left: A standard workflow translating one format to another with a fixed schema.
Right: A basic dynamic workflow that has a dynamic reader and writer.
Dynamic workflows are helpful if the structure of the source or destination data might change — in other words, if there’s a risk of schema drift. For example, new columns might be added to the source table, fields/columns might get renamed, or layers might be added or removed, requiring you to go back into FME and update your workspace to reflect the new schema if you’re not using a dynamic workflow. They’re also helpful if the data model isn’t well defined, say if you want your FME workspace to process a variety of tables that have different columns.
If you notice that your workspace has duplicated transformers, like the following screenshot, this could be a red flag indicating you can simplify the workspace using a dynamic reader and writer:
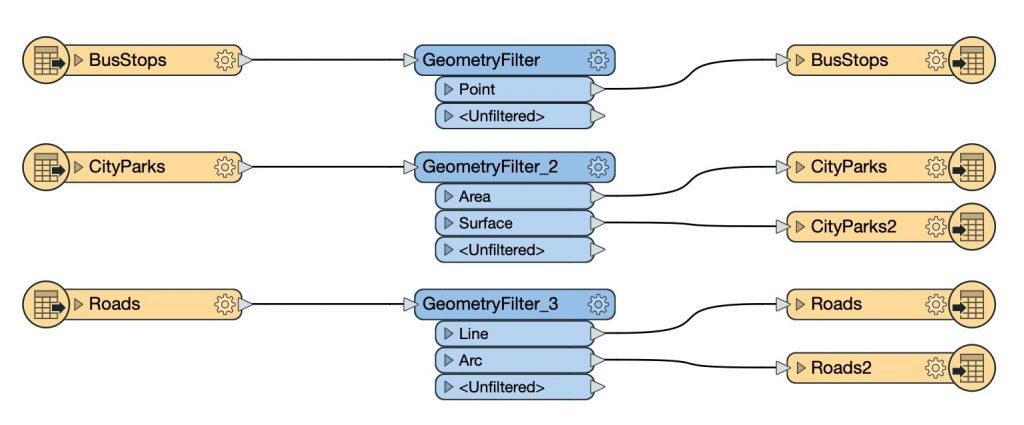
Red flag: This workspace has a lot of the same transformers running in parallel. Their parameters vary according to the input/output schema. This workspace would be more robust and easier to maintain as a dynamic workflow.
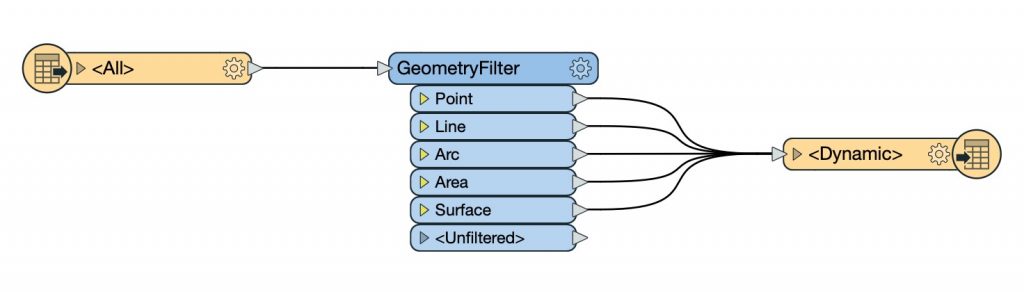
Similarly, if you have a lot of mirrored feature types on both sides of a workspace and you’re doing the same process to all of them, this is another indication that you could use a dynamic workflow:
Red flag: This workspace has the same set of feature types on both the reader and writer and the same processing is being applied to all of them. It would be more robust and easier to maintain as a dynamic workflow.
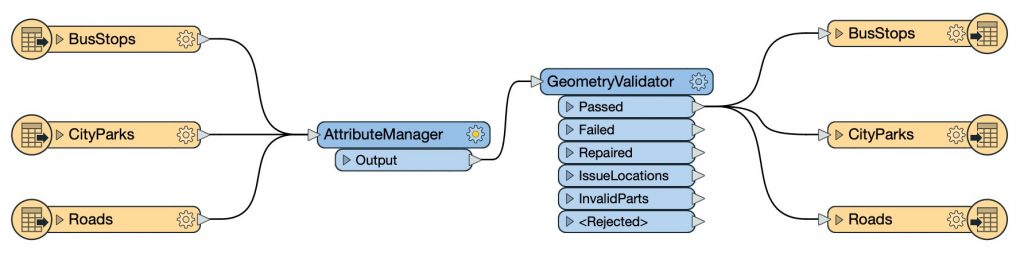
The solution is to design your workspaces to detect and handle schema changes and variations. This means allowing flexibility in terms of the feature type name (i.e. the table, sheet, feature class, etc.), attribute names and types (i.e. columns, fields, etc.), and geometry types, if applicable.
Improvement: The above workspace with the duplicated transformers has been made dynamic, which greatly simplifies it and makes it easier to maintain.
Building schema-independent FME workspaces
When you create a dynamic workflow, you’re telling FME to use the source schema or a template to generate the destination schema at runtime. This means you don’t need to know the source schema while you’re authoring the workspace.
When building a workflow using dynamic readers and writers, you’re allowing the workspace to accept a variety of source datasets with different schemas. If the data model changes at some point, updating the workspace won’t be necessary, because it will be able to handle changes in the incoming datasets.
The key is to tell FME where the desired schema comes from – do you want the destination schema to look like the source dataset, a different external dataset, a lookup table, or be generated from multiple sources? When the workspace runs, FME will get the schema from the place you specify and use it for the output.
For a step-by-step guide, we have a tutorial series on how to create dynamic workflows for different schema sources. Check it out on the FME Community:
You can also watch a demo of how to build dynamic workflows in the schema drift webinar. You’ll see how to set the reader and writer parameters to allow for flexible incoming feature types and to enable a dynamic schema definition.
Start building flexible, powerful workspaces with a dynamic workflow
A dynamic workflow offers more flexibility in that it can transform any input dataset regardless of its structure, minimizing the number of workspaces you need to create and maintain. We often see dynamic workflows used with FME Server to create self-serve data portals (like our FME-powered Easy Translator) because they can perform the same translation regardless of the input data model.
Dynamic workflows also make for easy workspace design and maintenance, because you won’t need to spend time updating the workspace every time the data model changes.
So give it a try! If you know what you want the output schema to look like – whether that’s a mirror of the source data, a template file, or something else – you can use our tutorial series to follow the step-by-step process of building your own dynamic workflow.


