
 As you might know, I’m British by birth, so queues and queueing come naturally to me.
As you might know, I’m British by birth, so queues and queueing come naturally to me.
The BBC says, the queue draws on “notions of decency, fair play and democracy.” It suggests that the queue for the Wimbledon tennis tournament is the ultimate, and having experienced it I have to agree. “The Queue” (as it’s known) even has its own official 30 page guide!
But although waiting in queues is equally fair, the actions at the end of the queue might not be. That’s why, for example, supermarkets have a special checkout for “ten items or fewer,” because one person with a monster-sized shopping list could block the queues for shoppers with just one or two items.
And when you think about it, the same issue applies to the queue in FME Server…
![]()
FME Server Queues and Engines
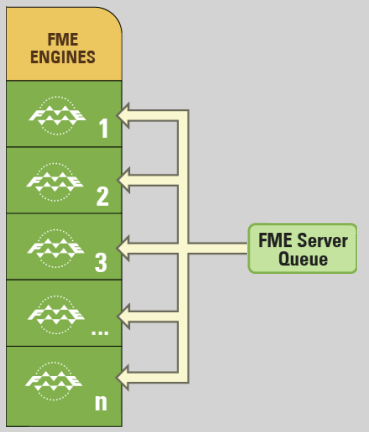 Up until recently FME had one queue and a number of engines. It generally worked because one particularly large job couldn’t block the queue; at most it would tie up just one engine. A user could route jobs to a particular engine, but only using config files, and could set priority only for each individual job.
Up until recently FME had one queue and a number of engines. It generally worked because one particularly large job couldn’t block the queue; at most it would tie up just one engine. A user could route jobs to a particular engine, but only using config files, and could set priority only for each individual job.
However, a large organization might have multiple users submitting multiple large jobs. In that scenario these jobs could hog all the engines and cause smaller (maybe more important) jobs, to get stuck waiting.
In short, it didn’t work where an organization had a number of departments with unequal requirements, where some users needed to share just a small part of a server for a small amount of time.
So in 2018 we added the ability to create multiple queues, and map them to multiple engines. This technique Don calls Server Capacity Management.
![]()
Adding Queues and Assigning Resources
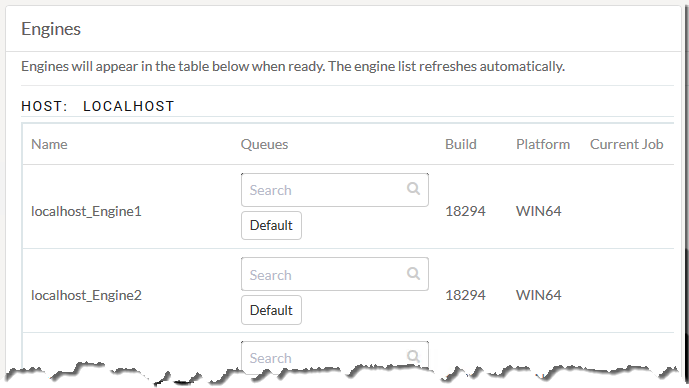
Here’s my FME Server installation as shown by the web interface. I have eight engines available:
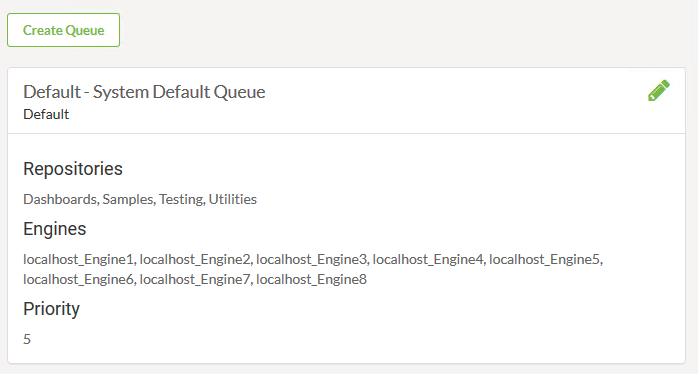
Underneath that I have a new table displaying a single default queue, but a button with which to create others:
So I can create a queue for the knowledge team (my team at Safe) to submit jobs:
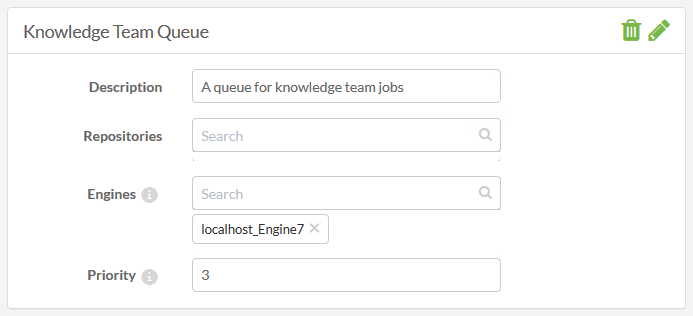
There is a Priority parameter because in 2018 you set job priority at the queue level. Job level priority is deprecated (although for now it still exists as an advanced parameter). A smaller number indicates a higher priority.
Notice that you assign the engine to the queue, not the queue to the engine. Here I’ve assigned Engine 7 to the queue, with a priority of 3. Engine 7 is also assigned to the default queue, but there its priority is 5. So if there are jobs in both queues waiting for an engine, and Engine 7 becomes free, the knowledge team jobs will get priority.
I could remove Engine 7 from the default queue completely, saving that engine only for jobs submitted to the knowledge team’s queue. Doing that makes the Priority setting redundant. Priority only has an effect where assigning the same engine to multiple queues.
Repositories
You’ll also have spotted that each repository can be assigned to a queue. Like engines, I assign the repository to the queue, not the queue to the repository. Unlike engines, each repository is assigned to a maximum of one queue. If I add a repository to a second queue, it must be removed from the first:
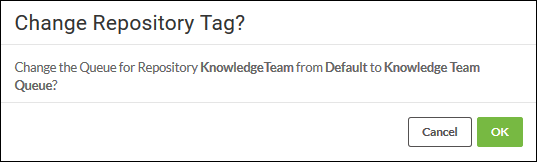
By default, FME assigns all jobs to the queue of their respective workspace repository.
So I could set up a Knowledge Team repository and assign that repository to a Knowledge Team queue. Or I might assign a Knowledge Team repository to a “Safe Staff” queue along with a Support Team repository, a Sales Team repository, etc.
Or I might not assign any repositories, in which case the user running the job specifies the queue to submit it to.
Speaking of which…
![]()
Specifying a Queue
The above section shows how system administrators set up a queue. However, there are also mechanisms for users to submit jobs to a specific queue.
First of all, if a repository is assigned to a queue, and the user is happy using that queue, then nothing need be specified. They just submit the job for processing.
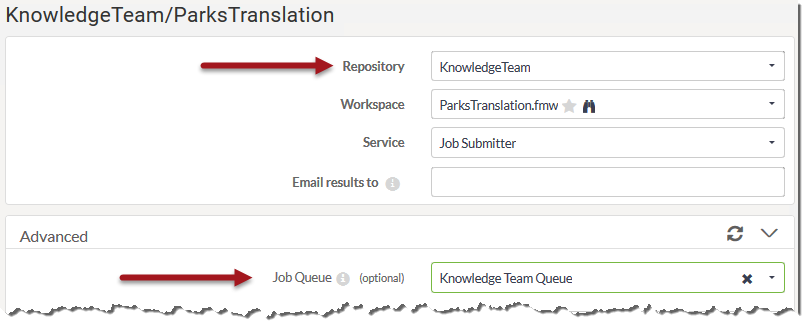
If a user wants to pick a queue at runtime, then they can do that in the web user interface:
Queues are also assigned (and managed) through the REST API. The command /transformations/jobroutes gives a way to create a tag (queue) and to assign an engine to that tag. Then a workspace can run using /transformations/submit with a tag set using TMDirectives in the transformation request.
What Ifs
- So what if I submit a job and don’t specify the queue?
- If the job repository is assigned to a queue, then the job enters that queue. If the repository is not assigned to a queue, then the job enters the System Default Queue.
- How about schedules?
- Yes, scheduled jobs can be assigned to a particular queue. So your daily update that takes four hours to run can be kept on a separate queue to other jobs.
- Does a distributed architecture have any effect?
- Of course. With a distributed architecture, engines can be on an entirely different machines. So the four hour daily update can be sent to a queue whose assigned engines are on separate servers.
Example Setup
Let’s say I have eight engines and am setting up queues for the support, knowledge, and QA teams at Safe. I might set it up like this:
| Queue | Repositories | Daytime | Nighttime | ||
|---|---|---|---|---|---|
| Engines | Priority | Engines | Priority | ||
| World Tour Demos | World Tour Demos | 1,2,3,4 | 1 | 1,2,3,4 | 1 |
| Server Playground Demos | 2,3,4 | 2 | 2,3,4 | 2 | |
| Support Team Short Term | Support | 3,4 | 3 | 3,4 | 3 |
| Support Team Long Term | Support | 7,8 | 3 | 7,8 | 5 |
| Knowledge Team | Knowledge | 3,4 | 3 | 3,4 | 3 |
| Short Term Tests | QA Short Term Tests | 5,6 | 4 | 5,6 | 3 |
| Long Term Tests | QA Long Term Tests | 7,8 | 4 | 3,4,5,6,7,8 | 4 |
So…
- World tour demos always have engine 1 to themselves. They share engines 2,3,4 but have priority on them. Other server demos have slightly less priority over the same engines.
- The support and knowledge teams share two engines (3,4) for short term jobs, with equal priority. The QA team have two engines (5,6) for their short term jobs.
- For long-term jobs, the support team shares engines 7 and 8 with the QA team. The support team get priority in the day, the QA team get priority at night.
- The QA team have access to engines 3-6 for long term jobs at night. But should any other jobs request those engines, those jobs get priority.
It’s important to remember that if the QA team starts a job on engine 3 at night, then it blocks other jobs on that engine. A job from the knowledge team that arrives later will not be able to interrupt a running job. It will, however, get priority once the QA team job is complete and the engine becomes free.
Also remember that queues and repositories are not fixed. A member of the knowledge team could still submit a job to the support queue instead of their own.
On Demand Changes
This new queuing system is very flexible because it is quickly and easily managed through the web interface.
But what’s better is that you can also manage queues using API calls (click to enlarge):
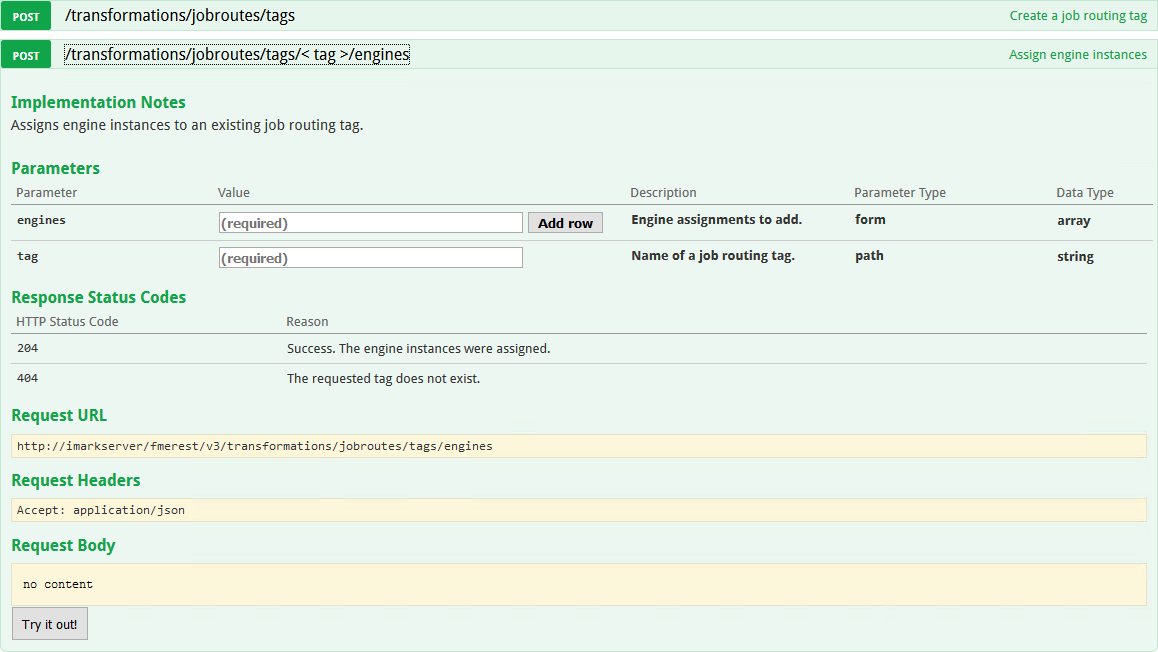
That means you could set up a scheduled process to remap queues at various times of day. For example, at 5pm you open more engines up to long-term jobs, and at 8am the next day, revert to more engines for short-term job queues.
![]()
Conclusion
So what does this all mean? Well, it means that you can fine tune FME Server to provide the best service at the best time to your entire workplace. Multiple queues allow greater flexibility and the option to separate large jobs from small.
It’s not as well documented as the Wimbledon queue system, but there’s way less etiquette to worry about, and it certainly provides better options when you’re managing server capacity.
And for more information about other new FME Server functionality, check out the Deep Dive webinar, or attend an upcoming FME World Tour event.

PS: In fact, Wimbledon has multiple queues too! One for the current day’s play, and one for the following day! Yes, people really do start queuing that far in advance when there are some interesting games on. And what do you get after queuing? Rained on…



