Adjacent Feature Attributes in FME: Reading Text Files

 Hi FME’ers,
Hi FME’ers,
I’m thinking I might not have really given much love to the Adjacent Feature Attributes functionality in FME, which is a pity since it’s a great tool for data processing.
And a question in a recent training course has given me a great example to demonstrate…
![]()
Adjacent Feature Attributes: What Is It?
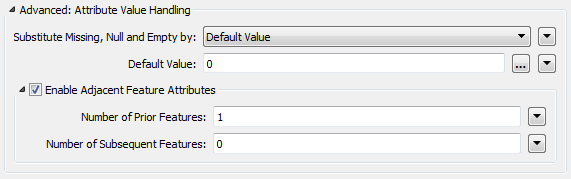
Let me first just explain what this tool is. Take a look at the AttributeManager transformer’s parameters and you’ll see a couple of advanced options at the top of the dialog:

Obviously the key parameter there is Enable Adjacent Feature Attributes, but – as I’ll show below – the substitution parameter is important for us too.
But what does it do? Well, remember that each feature in FME is usually processed separately (feature-based). There is a stream of data and each feature has its own attributes. Well, what this option does is let us reach out to adjacent features in the stream and access their attributes as well!
For example, in this exercise in the Advanced FME Desktop course, I set up the AttributeManager to have access to the preceding feature’s attributes:
We’re working with climate (rainfall) data which accumulates for the year (so February’s total is January+February, and March is January+February+March). Since I want to get a monthly figure I use the following:
![]()
i.e. the current month’s (current feature’s) rainfall is its cumulative total minus the cumulative total from the previous month (previous feature). You can see how the [-1] part tells FME that the value is to come from the previous feature’s attribute.
That’s a very quick example of how adjacent attributes work, and you can see that the substitution value is important because January doesn’t have a previous feature to subtract. Without setting a default value for that scenario, the workspace would fail.
But there are more complex scenarios than that…
![]()
Adjacent Feature Attributes: Text-Reading Example
The example I really wanted to demonstrate was one that occurs more often than rainfall data: reading data from a structured text file.
Unlike CSV files, where the data is spread horizontally and separated by a comma (or similar character), text files are often in a format where the data is spread over a number of lines, like so:
** Safe Software Employee File ** Name: Mark Team: Knowledge Team Position: Evangelist Twitter: @FMEEvangelist
It’s easily readable by a human; less so with software. That’s because these are often proprietary formats or structures, unique to the company or dataset, and so no standard solution exists. In some cases the structure can be quite complex – with an unknown number of header lines – where the ability to read it requires a certain amount of restructuring.
Training Question
The question that came up in training was asked by a user with data in this structure:
OVERALL HEADER --------------------------------------------------- SUBHEADER 1 SUBHEADER 2 SUBHEADER 3 --------------------------------------------------- ADDN, ID: XYZ FEATURE 12345 FEATURE 12346 FEATURE 12347 FEATURE 12349 FEATURE 12350 FEATURE 12351 ---------------- CHG, ID: XYZ FEATURE 12348 FEATURE 12352 ---------------- DEL, ID: XYZ ----------------
It’s essentially a changelog – a list of features to be processed. Some of them are being added (ADDN), some are being changed (CHG), and some need deletion (DEL). Reading this with the FME textline reader is straightforward, and it’s not too difficult to extract the features from the headers and separator lines.
The main difficulty is how to tell (for example) that FEATURE 12345 is an ADDN, since the “ADDN” part is defined in a header (let’s call it an Action Header) and just reading a feature by itself will not include the Action Header content. Additionally, the text structure is not fixed. There might not always be exactly six (6) additions, and in this case there aren’t any deletions at all. So we can’t make any assumptions using the number of lines or the file structure.
In the past one solution would have been to use the VariableSetter and VariableRetriever transformers. The Action Header is saved as a variable and applied to all subsequent features. But – to me at least – that’s not the best way to handle this data. Using variables like this requires the flow of features in the workspace to be predictable, and I prefer certainties over predictions!
So, instead of that, I came up with a solution using Adjacent Feature Attributes.
![]()
Adjacent Feature Attributes: Text-Reading Solution
I rushed through this solution while on a break in training, so it might stand a little improvement; but it does the job well enough. It reads the data with a TEXTLINE reader and uses two AttributeManager transformers to carry out the processing:
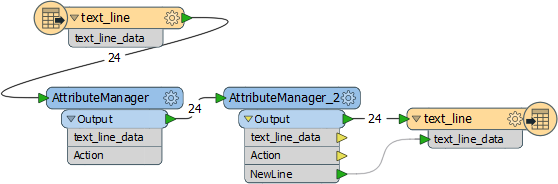
The first transformer cleans the Action Header, so “ADDN, ID: XYZ” becomes simply “ADDN”, using a set of conditional statements:
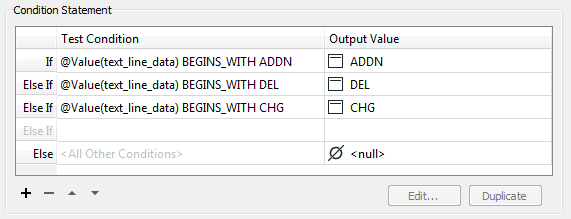
I could have used a Tester (to test for a header) and maybe a SubstringExtractor to pull out the action, but using conditions has two advantages. Firstly it fits everything into one nice, neat package. Secondly – and more importantly – note that the “Else” field is set to <null>. Each line that isn’t an Action Header gets a <null> action, denoting that we don’t know what to do with it yet. When we get to use the adjacent feature attributes, the <null> will trigger a substitution.
The Second AttributeManager
The top-level parameters for the second transformer look like this:
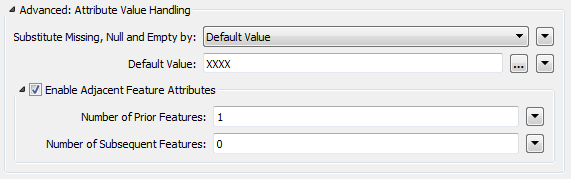
Basically we’re reaching out to the prior feature to find out what action that was. But not every line in the file has a previous action, so we set the default to XXXX.
Then we have some conditions going on:

The new Action field defines an action for that row of the data, depending on what we know about the previous feature. It looks like this:
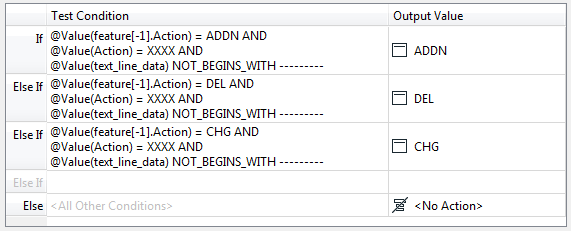
The logic is:
- IF the previous feature was an ADDN (or CHG or DEL)
- AND IF this feature doesn’t have an action
- AND IF isn’t a separator row
- THEN it too is an ADDN (or CHG or DEL)
The “IF this feature doesn’t have an action” is important. It basically means “Is this line an Action Header”? If it is then we don’t want to overwrite its action value with the previous one.
So, every feature is now tagged with the correct action. The NewLine attribute created is a new line incorporating the action, which FME writes to the restructured output file:

The logic is:
- IF the row of text does NOT begin with the action
- AND IF that action is NOT XXXX
- THEN it is a feature and has the action appended
- ELSE just use the original content
The first IF is checking again if this is already an Action Header (which would have the action recorded, but doesn’t need it appending).
The second IF is checking for any other header or separator lines (which would still have XXXX as their action)
Output
Finally FME writes the data to a text file. The result is:
OVERALL HEADER --------------------------------------------------- SUBHEADER 1 SUBHEADER 2 SUBHEADER 3 --------------------------------------------------- ADDN, ID: XYZ ADDN FEATURE 12345 ADDN FEATURE 12346 ADDN FEATURE 12347 ADDN FEATURE 12349 ADDN FEATURE 12350 ADDN FEATURE 12351 ---------------- CHG, ID: XYZ CHG FEATURE 12348 CHG FEATURE 12352 ---------------- DEL, ID: XYZ ----------------
Now it’s a lot easier to read the data and know immediately which action a particular row is associated with.
![]()
Summary
So that was a short example of Adjacent Feature Attributes, and also included Conditional Values. It’s one of those workspaces I don’t know if I like. It’s not simple enough to be obviously correct, but it’s too complex to tell that it’s obviously wrong! And I did create it in a rush.
Looking back I wonder why both AttributeManager’s needed a different substitute value. I think it’s because the first (<Null>) defines when a line has no action. But then, because we’re using adjacent features, I need a different substitute to handle the top row (which doesn’t have a prior feature).
Anyway, I don’t know if there are many easier solutions. The Adjacent Feature Attributes enable us to fetch the action from the prior feature and the rest is all testing to make sure that a new Action Header is not overwritten. That’s fairly simple.
There are two specific items of interest.
Firstly all features fetch the updated version of the previous feature’s action. For example, feature 12345 is updated with an action from the Action Header, but feature 12346 is updated with the new action applied to feature 12345. I’m trying to say that Adjacent Feature Attributes are dynamic, and take into account what has already occurred.
Also, in the second transformer, the second condition depends on the first. In other words this too is dynamic and the order in which I place these conditional attributes is important. It means I didn’t need to generate the action in one transformer and then use a further transformer to process it; I just used one transformer.
I hope this small example is of interest to you. If you want to examine the workspace then you can find it on Dropbox.