AI Agent Architecture: Tutorial & Examples
AI Agents are intelligent systems that can perform tasks autonomously on behalf of a user or another system. They can break down a larger goal into smaller, manageable tasks and plan the execution sequence to achieve it.
Unlike traditional pre-defined and hard-coded workflows, AI Agents can assess the advantages and disadvantages of decisions and select the best alternative among several options for executing a task.
This article explains the architectural concepts behind AI agents, introduces frameworks that help implement them, and provides the best practices to help you get started on your agent implementation.
Summary of key AI agent architecture concepts
| Concept | Description |
|---|---|
| AI agent | An AI agent is an autonomous system capable of performing tasks on a user’s or another system’s behalf. It makes autonomous decisions about the steps it needs to execute to accomplish the goal. |
| AI agent architecture | Key components include LLMs, memory, functions, tools, and routing capability. |
| Memory and state management | AI agents must remember past interactions and the state of the sequence of tasks to make appropriate decisions. |
| Functions and external integration | AI agents rely on external functions, tools, or sub-agents to complete tasks. Agent architecture must be able to discover these external resources and invoke them to achieve the desired end goal. |
| Routing based agents | Routing refers to redirecting a user input and context to relevant functions or sub-agents within the agentic system for further processing. Routing can be rule-based, semantic, LLM-based, hierarchical, or auction-based. |
| ReAct agents | ReAct agents (short for reason and act) rely on a loop that prompts LLMs iteratively until the LLM breaks down a request into the four components required for task execution, namely: thoughts, actions, action inputs, and observations. |
| Implementing AI agents | To implement an agentic workflow, one can write custom code and use an SDK to access an LLM via its API or write code for agentic models like OpenAI Operator or Claude Computer Use. Frameworks like LangGraph can accelerate AI agent development by defining agentic workflows as directed graphs, where nodes represent agents or functions. Finally, no-code yet customizable frameworks like Safe FME allow users to build workflows and data pipelines and connect to popular LLM models via a user interface and pre-built integrations. |
Understanding AI agent architecture
AI agents are autonomous systems that can execute complex logical tasks on behalf of a user by retrieving additional information, recalling historical interactions, and programmatically invoking external tools to take action, as illustrated below.
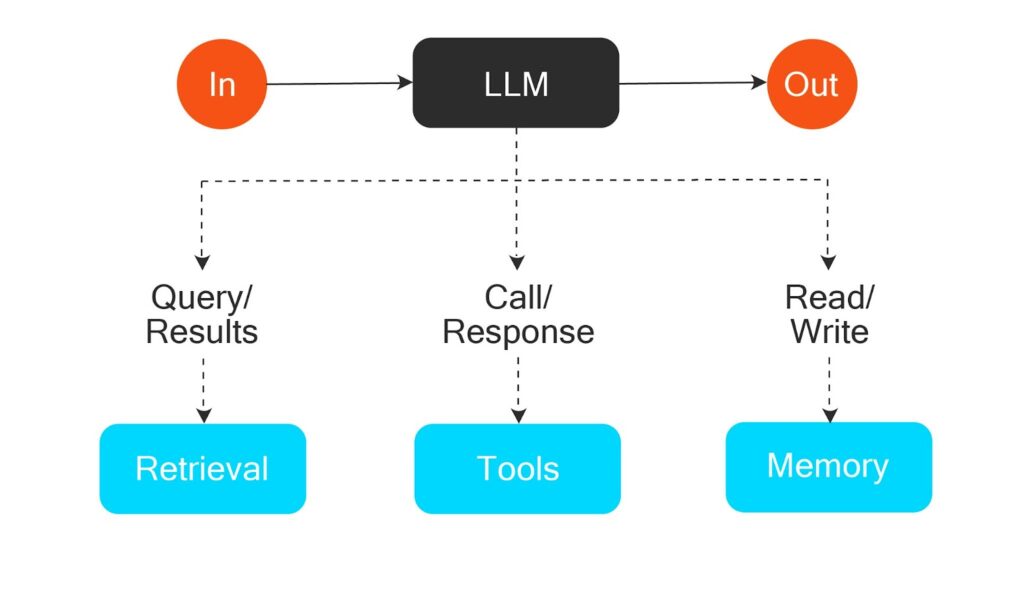
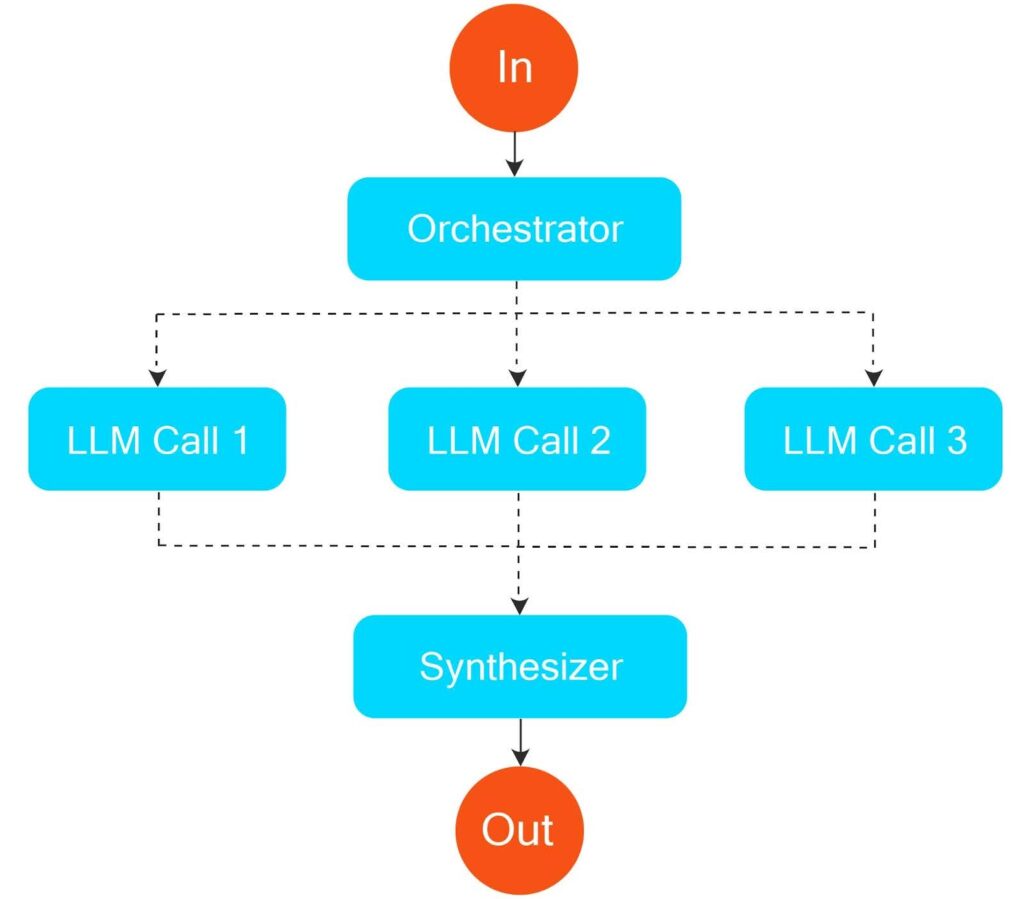
AI agents differ from workflows that rely on programmatically specified and predefined logical flows using LLMs, like the example below, where pre-determined logic breaks down tasks, dispatches prompts to LLMs in parallel, and synthesizes the result.
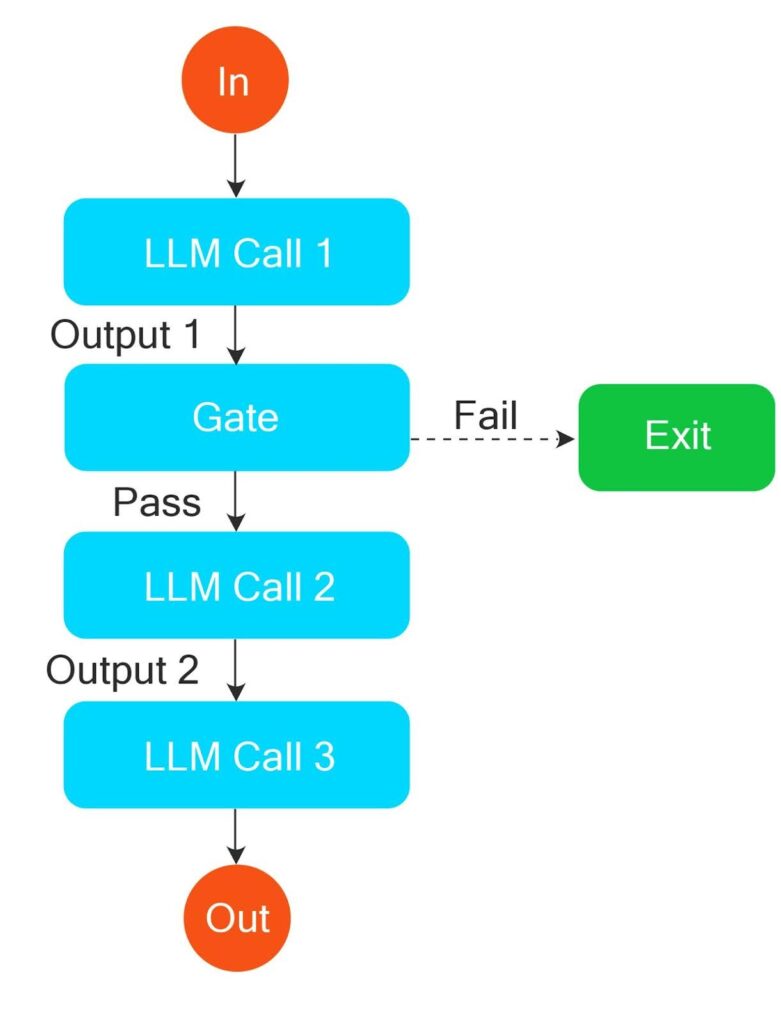
Pre-determined workflows don’t always call LLMs in parallel, they might do so I sequentially using the prompt chaining technique, where the output of one LLM is fed as input to another specialized LLM, as shown below.
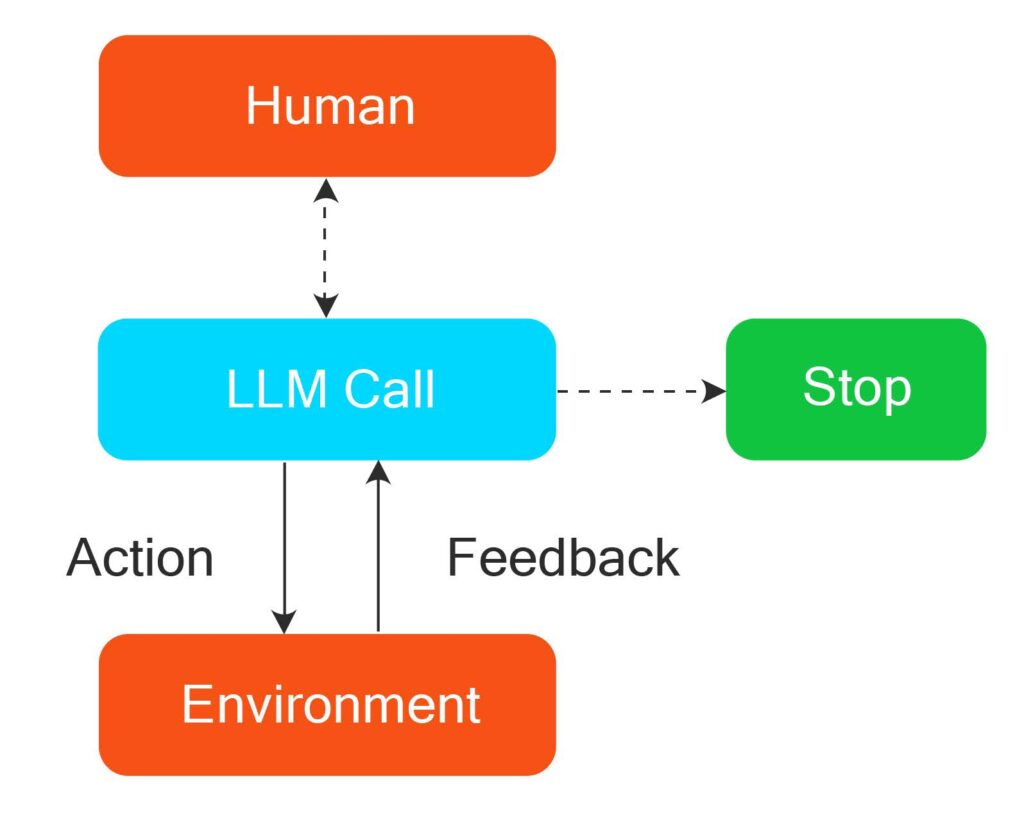
AI agents, on the other hand, can independently decide the number of steps and the sequence of their execution. Unlike workflows, their execution sequence is not predefined. Hence, agents can be used for open-ended problems where it is difficult to map the execution steps and their sequence beforehand, as illustrated below.
Key components of AI agents
Broadly speaking, an AI agent has three key components.
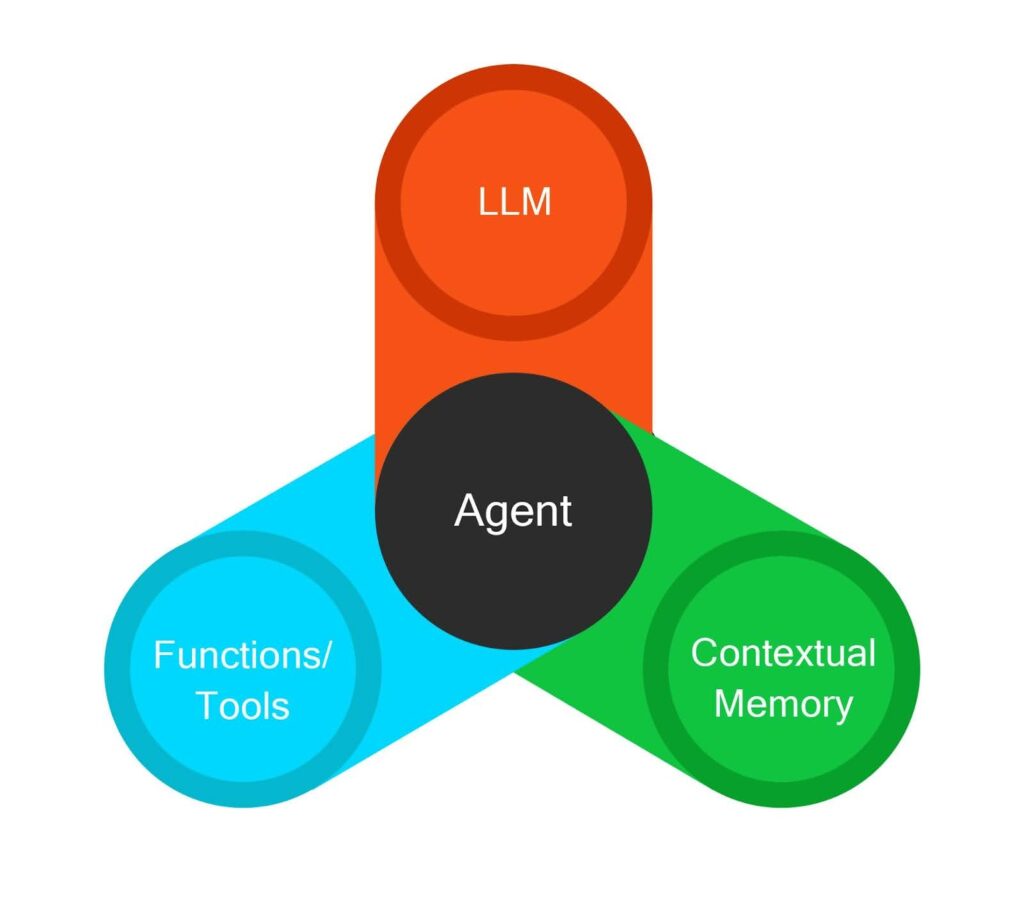
LLMs
LLMs provide the intelligence for the planning and execution of tasks. LLMs receive the user input and create a plan of the sequence of actions needed to achieve the user’s goal. Based on the Agent’s implementation logic, there may be recursive calls to LLMs to figure out the individual tasks within a larger task, the sequence of execution, and the feeding of output to other child tasks.
Contextual Memory
Contextual memory stores information about the previous steps executed by the agent. This is important in patterns where an agent needs to refer to the outcome or state of a previous step before proceeding with its task. For example, consider a management assistant agent who answers questions about an organization’s sales and regions. A user can begin with the question “Which region had the lowest sales this month?” and then follow it up with “Which product had the highest sales in this region?”. Here, the agent will need a reference to the outcome of the previous question to process the question. Agents use short-term contextual memory to handle such requirements.
Contextual memory can also be long-term. For example, consider the same agent conversing with user A, who always asks questions about a particular region. That information can be stored in long-term memory as an area of interest for that user. Next time, if a question from the same user does not specify any region names, the agent can assume this region as the subject and confirm it.
Functions, API Calls, and Sub-agents
AI agents often need to access external systems to execute their tasks. They may need to fetch information from an external system, perform an operation using another system, or even delegate a task to another agent in a different domain. Such integrations are a key element of AI Agent architecture. For example, the assistant agent in the example may need to fetch information about sales from an external ERP platform. It may first fetch information about the logged-in user from an identity access management platform and then use an API from the inventory platform to query the information the user is privileged to access.
Of late, several frameworks have emerged to standardize function calling while building agents. Anthropic’s model context protocol (MCP) is a popular framework in this area. MCP is an open protocol that lets developers expose data and functionalities required by agents in a standard format.
Sub-agents are agents specialized in handling a specific domain or sub-task. They help to bring modularity within the AI agent architecture. Consider building functionality to suggest methods to improve sales within the assistant agent we discussed earlier. Building the data analysis and management reasoning functionality within the same assistant will make the logic overly complex. In all likelihood, this functionality will need a different LLM or a fine-tuned LLM. Such requirements are handled by building sub-agents that complement the main agent.
Architecture patterns
Routing-based Agents
The extent of the Agent’s autonomous nature depends on how well it uses the above components based on its intelligence without the programmer defining a sequence of steps. For example, suppose the Agent can plan the sequence of functions it needs to execute while considering the elements stored in its memory. In that case, it is a truly autonomous agent. In reality, this is difficult to accomplish, and one needs to build boundaries and guardrails around the agent’s decisions to ensure reliability. A predefined routing process is one element that helps to bring predictability to agent decisions.
Routing is the process of deciding which function or agent to trigger as the next step. Below are the key routing patterns used in agent architectures.
- Rule-based routing: Here, the functions are called based on predefined rules defined in the application code. Rules can be as simple as detecting the presence of a word in the input and redirecting based on it.
- Semantic Routing: Semantic routing considers the meaning of input to decide the relevant function. This is implemented by understanding the intent and redirecting the request to a function or sub-agent. Understanding the intent is usually done using a language model.
- Hierarchical routing: This mechanism is used in multi-agent patterns where a master or primary agent is responsible for delegating tasks to sub-agents.
- Auction-based routing: Here, each sub-agent gets access to the input, and they bid for the right to perform a task. The bid can be in terms of cost, time, or any other parameter. The agent with the most efficient bid becomes responsible for the task.
- LLM-based routing: In this case, an LLM decides the relevant function or sub-agent to call based on user input. The LLM is given access to the function and sub-agent metadata to make this decision. This pattern, where an LLM is in charge of routing and orchestration, is the true definition of an AI agent, as opposed to a pre-defined agentic workflow.
ReAct Agents
ReAct is a prompting strategy that stands for “reason and act.” The basic ReAct prompt asks LLMs to process the original user input by structuring it into four components: thoughts, actions, action inputs, and observations. The ReAct logic runs this in an infinite loop till the LLM concludes that it has the correct answer. The ReAct loop-based agents are more autonomous than router-based agents because of their ability to plan the steps, evaluate the outcomes, and execute. The disadvantage is that it is difficult to impose guardrails, and there are possibilities of the LLMs running away with recurring calls and exploding costs.
Human In-the-loop Agents
In many cases, it may not be possible to let an agent act truly autonomously because of the possibility of errors, hallucinations, or simply compliance regulations related to manual verification. Human-in-the-loop agents help to integrate human decision-making into the agent execution flow by triggering an interrupt at relevant places. The interruptions enable agents to wait for humans to approve or add additional information before proceeding to the next section.
Reflective Agents
Reflective agents help improve the quality of an agent’s output by adding a layer for the LLM to criticize its own output, learn from experiences, and self-improve. The implementation logic involves running the reflection or criticizing loop a predefined number of times to ensure the agent’s decisions are refined before they are used for calling other tools or functions. Reflection can be added as an additional layer for any agent architecture pattern, like routing or ReAct agents.
Implementing AI agents
To implement an AI agent, one needs to assemble the four core components of the agent architecture—namely, LLMs, contextual memory, external functions or sub-agents, and the routing functionality.
One approach would be to integrate these components based on custom code. However, such a manual approach would make it challenging to build a modular abstraction layer and implement scalable software engineering practices.
An alternative is to use AI agent frameworks and platforms that provide reusable components and abstraction layers to build an AI agent application. AI agent frameworks help implement agents by providing readily usable modules for LLM access, maintaining state and context, external function calling, and routing.
There are two kinds of AI agent frameworks: code-based solutions and no-code or low-code solutions.
Code-based AI agent platforms
Code-based solutions are frameworks in popular languages, like Python or Java, that engineers can use to implement AI agents. At a high level, developers can add them as dependencies in their source code and use the built-in functions to create agents. A few of the popular code-based AI agent frameworks are:
- LangGraph: LangGraph is a Python framework that extends LangChain to create and manage complex, stateful, and multi-agent workflows using graph-based execution. It allows developers to define workflows as directed graphs, where nodes represent agents or functions, and edges define execution flow. This enables structured decision-making, parallel processing, and dynamic interactions between AI agents.
- CrewAI: CrewAI is a multi-agent platform that enables the implementation of agents through several built-in functions and configuration files. CrewAI uses the concept of the “crew” to represent the larger organization that groups individual skilled agents within it. It supports workflows through the concept of processes. CrewAI’s enterprise version includes agent monitoring, logging, and a control panel.
Agent Implementation Using LangGraph
Let’s use LangGraph to build the management assistant agent we introduced in the initial sections. We aim to build an agent that answers questions about regional sales using available tools.
Begin by assembling all the required import statements and initializing the LLM. We will use OpenAI as the LLM in this example.
from langgraph.graph import MessagesState
from langchain_core.messages import HumanMessage, SystemMessage
from langgraph.graph import START, StateGraph
from langgraph.prebuilt import tools_condition
from langgraph.prebuilt import ToolNode
from IPython.display import Image, display
# Import things that are needed generically for tools
from langchain.pydantic_v1 import BaseModel, Field
from langchain.tools import StructuredTool
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
# Importing necessary types from the typing module
from typing import TypedDict, List
# Load environment variables
load_dotenv()
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)Now, we build a simplistic function that fetches some hard-coded data about the sales in each region. You will use the StructuredTool class within the LangGraph framework to register a function as an LLM tool.
class Region(BaseModel):
region: str = Field(description="Region")
def get_current_sales(region: str) -> int:
# Here we are passing hard-coded value but can be integrated with sql based database
sales = {'colorado':130,
'california':220,
'arizona':140,
'newyork':400}
return sales[region.lower()]
sales_data = StructuredTool.from_function(
func=get_current_sales,
name="Get_Sales",
description="Get the current sales from a region, in million USD",
args_schema=Region,
return_direct=False,
)Now, we build a simple function that can do a subtraction operation. LLMs aren’t designed to query a SQL database or do math. Hence, handling calculations programmatically and exposing them as functions is always better.
class Substraction(BaseModel):
number_a: int = Field(
description="The number from which another number is to be subtracted"
)
number_b: int = Field(description="The number to be subtracted")
def get_difference(number_a: int, number_b: int) -> int:
return number_a - number_b
data_difference = StructuredTool.from_function(
func=get_difference,
name="Difference",
description="Find the difference between two numbers",
args_schema=Substraction,
return_direct=False,
)The next step is to expose these tools for the LLM to use. We use the bind_tools function from Langgraph to do it.
data_tools = [sales_data, data_difference]
llm_with_tools= llm.bind_tools(data_tools)Stitch the functions and LLM together to create an agent. The below snippet creates a graph using LangGraph’s default StateGraph class. The code uses the built-in class MessageState to provide short-term memory for the agent about its previous output.
# System message
sys_msg = SystemMessage(content="You are a helpful assistant.")
# Node
def assistant(state: MessagesState):
return {"messages": [llm_with_tools.invoke([sys_msg] + state["messages"])]}
# Graph
builder = StateGraph(MessagesState)
# Define nodes: these do the work
builder.add_node("assistant", assistant)
builder.add_node("tools", ToolNode(data_tools))
# Define edges: these determine how the control flow moves
builder.add_edge(START, "assistant")
builder.add_conditional_edges(
"assistant",
tools_condition,
)
builder.add_edge("tools", "assistant")
react_graph = builder.compile()Trigger the agent using an input message and view the output.
messages = [HumanMessage(content="which region has higher sales - colorada or arizona? . What is the difference between them")]
state = react_graph.invoke({"messages": messages})
state["messages"][-1]The output will be as follows. It includes the LLM’s entire output, including parameters such as the number of tokens used in processing the request, or the model version number, which are often used for troubleshooting.
AIMessage(content='Arizona has the higher sales at 140 million USD, while Colorado has sales of 130 million USD. The difference between them is 10 million USD.', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 33, 'prompt_tokens': 214, 'total_tokens': 247, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_name': 'gpt-4o-mini-2024-07-18', 'system_fingerprint': 'fp_b376dfbbd5', 'id': 'chatcmpl-BH6QswQUYl3yWJSjw4AcAjppIACZV', 'finish_reason': 'stop', 'logprobs': None}, id='run-f7783771-7982-4493-a81d-c330d98e7ee4-0', usage_metadata={'input_tokens': 214, 'output_tokens': 33, 'total_tokens': 247, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}})The agent found Arizona to have the highest sales and used the subtract function to find 10 million as the difference between them.
The downside of the above approach is the obvious engineering skillset required to implement it and the challenge of maintaining it with ever-changing data. LangGraph is not an easy framework to master and hides many key details of agent implementation behind its built-in functions. Making sense of all the built-in functions will require considerable effort to understand agentic concepts and LangGraph’s engineering concepts. Another problem with building agents using LangGraph is the difficulty in debugging the path taken by the agent. Only someone with a strong programming background can make sense of the error messages and the schema definitions used by LangGraph. This is where no-code agent development platforms have an advantage.
No-code AI agent platforms
No-code agent development platforms help build agents through a visual interface. They have several built-in components that can be dragged and dropped onto the canvas to create complex flows. They also support popular databases and cloud platforms, allowing one to integrate data with agents without writing code.
FME By Safe
FME is a no-code data platform that integrates enterprise data with AI. It is an Any Data All AI platform that lets developers build actionable insights with mouse clicks. Beyond relational and nonrelational databases, FME provides support for GIS, spatial data, and IoT technologies.
Typical enterprise requirements to integrate AI deal with processing large amounts of unstructured or structured data and then using the agents to make sense of it. This is where no-code platforms have an edge. If a simple example like fetching data from a hardcoded list took tens of lines of code with LangGraph, you could imagine the number of lines of code required to work with Geospatial data, transforming it into a standard format, and analyzing the data, all using LLMs.
With no-code platforms like FME, creating a data pipeline and feeding it into an LLM can be accomplished by defining visual workflows using built-in components and relying on LLMs to do the bulk of the work, as illustrated below.
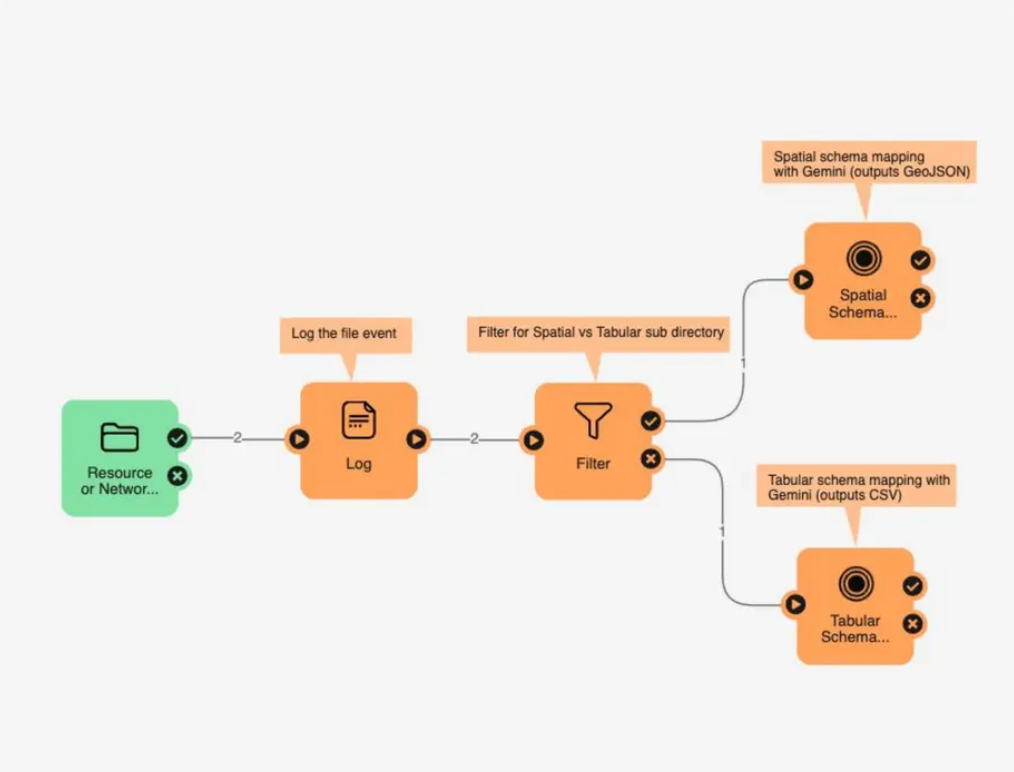
You can watch more about how FME helps Google to standardize geospatial data schema here.
Best practices while building agents
Building agents is a relatively new field with many options and decision points. The following section provides a list of best practices that can help you in your AI agent development journey.
Adopt a simple, scalable architecture and workflow pattern
The field of AI is changing rapidly, with new LLM versions and reference architectures being released weekly. This makes it tempting to design overly complex workflows involving multiple technologies. In addition, agent runaways due to system complexity can result in expensive usage spikes in operations. These risks make it safer to choose a simple and scalable workflow pattern. For most use cases, a router pattern is more than enough.
Establish evaluation metrics
One of the main challenges of an agent is ensuring the consistency of response. You may get a great result one day and see a completely different response with the same input another time. Hence, it is important to measure the accuracy of your agents and record it to understand the failure points and their frequency. Organizations must establish metrics regarding the accuracy, performance, cost, and consistency of agents early in the life cycle. Don’t launch an application into production without having an LLM testing strategy.
Invest time in prompt engineering before fine-tuning
Getting the best out of an LLM requires considerable effort in prompt engineering. A common mistake developers make while dealing with LLM inconsistency is attempting fine-tuning as the first measure. Fine-tuning is a costly process, and inferring from a fine-tuned model is particularly expensive, especially for cloud-hosted LLMs. In most cases, the same result can be achieved by investing time in prompt engineering.
Prioritize the quality of data and metadata
The success of AI agents depends heavily on the data provided as context. The data must be of high quality and have the required metadata and lineage. Agents rely on information about data to choose their execution path. AI-enabled data platforms with built-in agent development tools can help organizations handle all these aspects in one place. Tools like FME help integrate high-quality data while building agents.
Adopt a no-code AI agent platform
Since the LLM landscape is evolving rapidly, selecting an AI agent platform that abstracts integration with LLMs and third-party tools is essential so you can replace them over time with the need for refactoring your agentic application. Specifically, no-code platforms allow business analysts with no programming skills to integrate their data into the AI agent application workflow and maintain it on their own, which can have a substantial impact on organizational adoption and project success.
The following are must-have features for any no-code AI agent platform:
- Support dozens of integrations with third-party tools
- Support for all popular LLMs
- Built-in features to manage contextual memory and state
- Support for popular workflow patterns
- Support for building data pipelines to ingest from dozens of sources using built-in integrations and transform the data into a common format
- Support for customized extensions to accommodate advanced use cases
Implement guard rails and context filtering
Implementing an AI agent that knows everything and solves everything independently is a great dream. But in reality, AI systems require constraining to meet industry regulations, ensure data privacy, remain cost-effective, and avoid hallucination.
While building enterprise agents, it is important to limit LLM output within defined boundaries wherever possible. Always err on the side of deterministic responses by setting the temperature as 0 (a parameter that controls the randomness and creativity of the model’s output), even though this limits the creativity of the LLM response, before increasing it once you gain confidence.
Last thoughts
AI agents are autonomous systems that can execute tasks on behalf of a user or a system. Such an autonomous system can save costs, improve the speed of delivery, and provide better customer experience. The architecture of an agent includes LLMs, contextual memory, and external function integrations.
Building agents can be done in several ways. The most basic way is to write custom code to integrate LLMs with long-term memory and external tools and functions; however, this approach doesn’t scale and is hard to maintain. Code-based agent development frameworks, like LangGraph and CrewAI, can reduce the learning curve but require a dedicated development organization. No-code agent platforms like FME can help reduce this effort by providing a visual interface, pre-built connectors to third-party tools and LLMs, a scalable architecture, and customer support.
Continue reading this series
AI Agent Architecture: Tutorial & Examples
Learn the key components and architectural concepts behind AI agents, including LLMs, memory, functions, and routing, as well as best practices for implementation.
AI Agentic Workflows: Tutorial & Best Practices
Learn about the key design patterns for building AI agents and agentic workflows, and the best practices for building them using code-based frameworks and no-code platforms.
AI Agent Routing: Tutorial & Examples
Learn about the crucial role of AI agent routing in designing a scalable, extensible, and cost-effective AI system using various design patterns and best practices.
AI Agent Development: Tutorial & Best Practices
Learn about the development and significance of AI agents, using large language models to steer autonomous systems towards specific goals.
AI Agent Platform: Tutorial & Must-Have Features
Learn how AI agents, powered by LLMs, can perform tasks independently and how to choose the right platform for your needs.
AI Agent Use Cases
Learn the basics of implementing AI agents with agentic frameworks and how they revolutionize industries through autonomous decision-making and intelligent systems.
AI Agent Tools: Tutorial & Example
Learn about the capabilities and best practices for implementing tool-calling AI agents, including a Python-based LangGraph example and leveraging FME by Safe for no-code solutions.
AI Agent Examples
Learn about the core architecture and functionality of AI agents, including their key components and real-world examples, to understand how they can complete tasks autonomously.
No Code AI Agent Builder
Learn the benefits and limitations of no-code AI agent builders and how they democratize AI adoption for businesses, as well as the key components and features of these platforms.
Multi-Agent Systems: Implementation Best Practices
Learn about multi-agent systems and how they improve upon single-agent workflows in handling complex tasks with specialised roles, communication, coordination, and orchestration.
Langgraph Alternatives: The Top 6 Choices
Learn about LangGraph, a powerful yet complex orchestration framework for building intelligent systems, and its limitations, alternatives, and selection criteria.
Agentic AI vs Generative AI
Learn the differences between generative AI and agentic AI and how to choose the right AI paradigm for your needs.