
“Hey [Siri/Google], find the nearest coffee shop”
Have you ever wondered how the virtual assistant that you carry around in your phone is able to find nearby businesses? Technically speaking, this all starts with voice recognition… but let’s save that for another time. Today we’re focusing on the spatial analysis that is going on behind the scenes.
Spatial analysis tries to describe, explore, and explain patterns and relationships of topology, geography, and geometry. We use spatial analysis techniques to answer questions about relationships between objects by filtering, measuring, and overlaying spatial data. There are many types of spatial analysis, and we’ll get into a few in this article, but first let’s get some coffee.
Behind the Scenes of Spatial Analysis
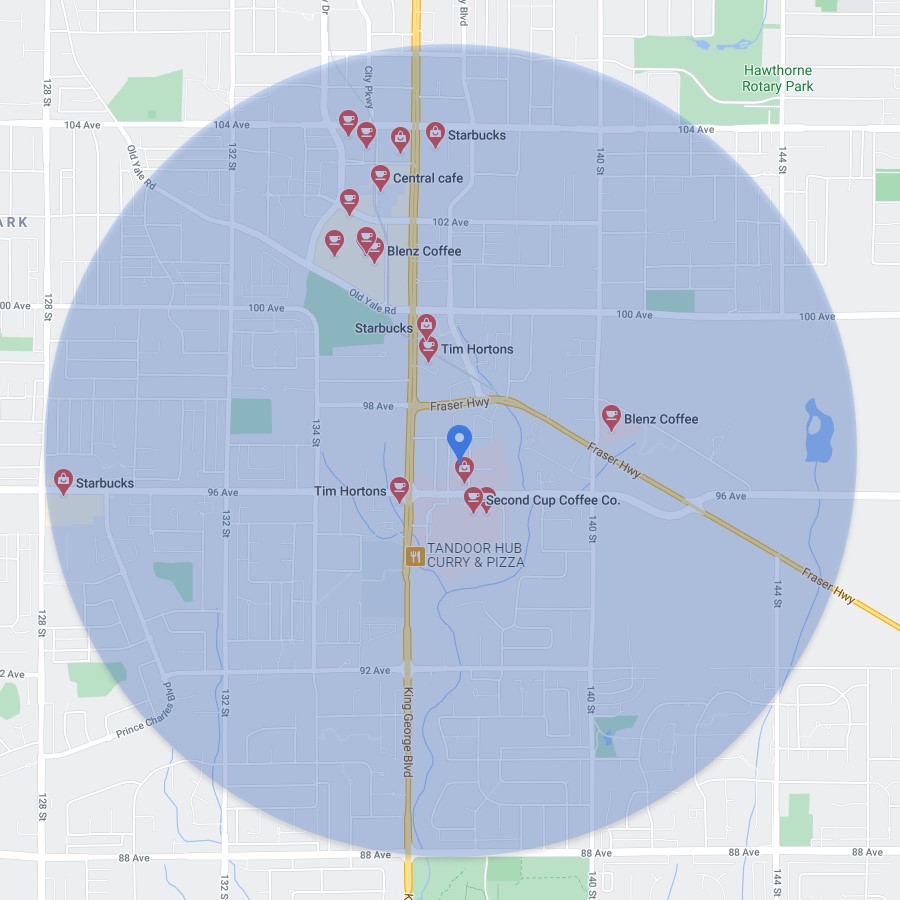
Okay, so you would never actually say that, but that’s basically how your virtual assistant interprets your “nearest coffee shop” request. Let’s break it down:
- Determine location — To begin, we need a starting point. So your virtual assistant will tap into your handy dandy, built-in GPS to see where exactly you’re located in the world.
- Create a buffer area of interest to perform overlay — This is your area of interest. We only care about the closest coffee shop, so there’s no need to include coffee shops from across the country. We want to get you your coffee ASAP, so less is more in this case.
- Calculate distance — Of the coffee shops within your buffer area, how far is each one of them from where you’re currently located?
- Create a route — Let’s get you that coffee!
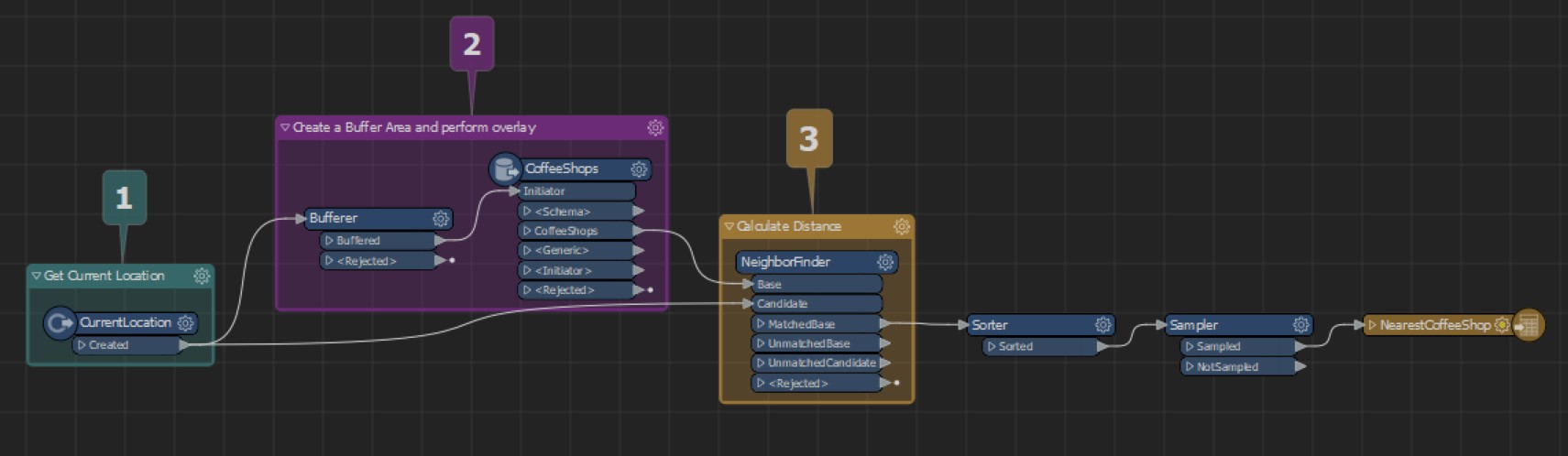
This FME workspace shows how your location (1) can be used as a data point along with coffee shop data (2) to determine which shop is best suited for you (3).
One of the most powerful things about spatial analysis is the ability to incorporate multiple datasets into your analysis. In the example above, we are measuring the distance between two points: your current location and the coffee shops.
Additionally, we’re creating a temporary polygon dataset, a buffer area, that will allow us to speed up our analysis by reducing the number of coffee shops we want to include in our analysis.
By combining data and applying three spatial transformations (Buffer, Point on Area Overlay, and Nearest Neighbor), we are able to determine which coffee shop is closest!
Filtering: The Muscle Behind Spatial Analysis
So far we’ve only been worried about which coffee shop is geographically closest to us. But what if you also wanted to know which coffee shop serves ethically sourced coffee?
Just like your coffee, your analysis is made the way you want it.
One of the most common steps in spatial analysis is filtering features based on attribute values. This can be as simple as filtering for a boolean value (ie. “x = true/false”) or more complex methods like regular expressions and composite test criteria. For example, if our coffee shop dataset includes attribute data about whether the vendor uses ethically sourced beans, we can use this information to filter out unwanted coffee shops that do not meet our search criteria (i.e. ethically sourced = true). If your source dataset does not have attributes, you may be able to join additional datasets or create new attributes based on a calculation.
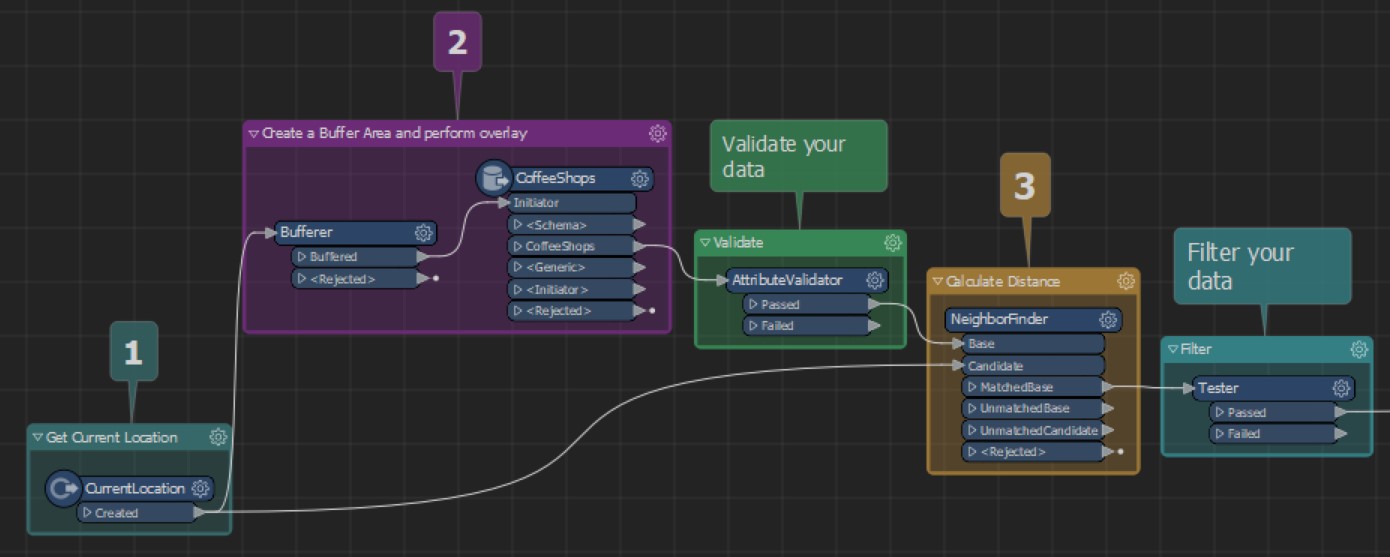
By adding in a validation step in your FME workflow, you filter out any coffee shops you’re not interested in and only keep those that meet your requirements.
Regardless of what attributes your data does or doesn’t have, it’s worth noting that a complete dataset will help make your analysis more thorough and ensure you get an accurate output.
If you’ve ever had a bad coffee, you know there is no amount of sugar and/or cream that can salvage the taste. Chances are the beans went stale and now you’re stuck with a hot cup of disappointment.
The same is true for spatial analysis, or any type analysis for that matter. If you start with bad beans (input), you’ll end up with a bad coffee (output). This is why it’s so important to validate your data and use high quality datasets in your analysis. Using quality source datasets will help ensure your analysis produces accurate results.
Route Analysis: Direct Me In the Right Direction
We know what coffee shops are around that suit our needs, but we don’t know how to get there. Time to do some route analysis. Route analysis is the process of determining an optimal path from origin to destination. This may include the shortest path, the path that requires the fewest left turns, or the path that takes you past your favourite pastry shop to grab a bite before you get your coffee.
Route analysis is possible in this situation because roads are topological networks that are made up of nodes (intersections), and edges (roads) which allow us to make calculations based on a source node (current location) to a destination node (coffee shop) on the network. Topological networks define the spatial relationship between connecting or adjacent features in a geographic dataset.
Why is this important? In most cases, you aren’t able to walk or drive in a straight line to get from point A to B. Rather, you need to traverse your way through a street network in order to get to your destination. That may include walking or driving along streets and making a left or right turn at an intersection to get to your destination.
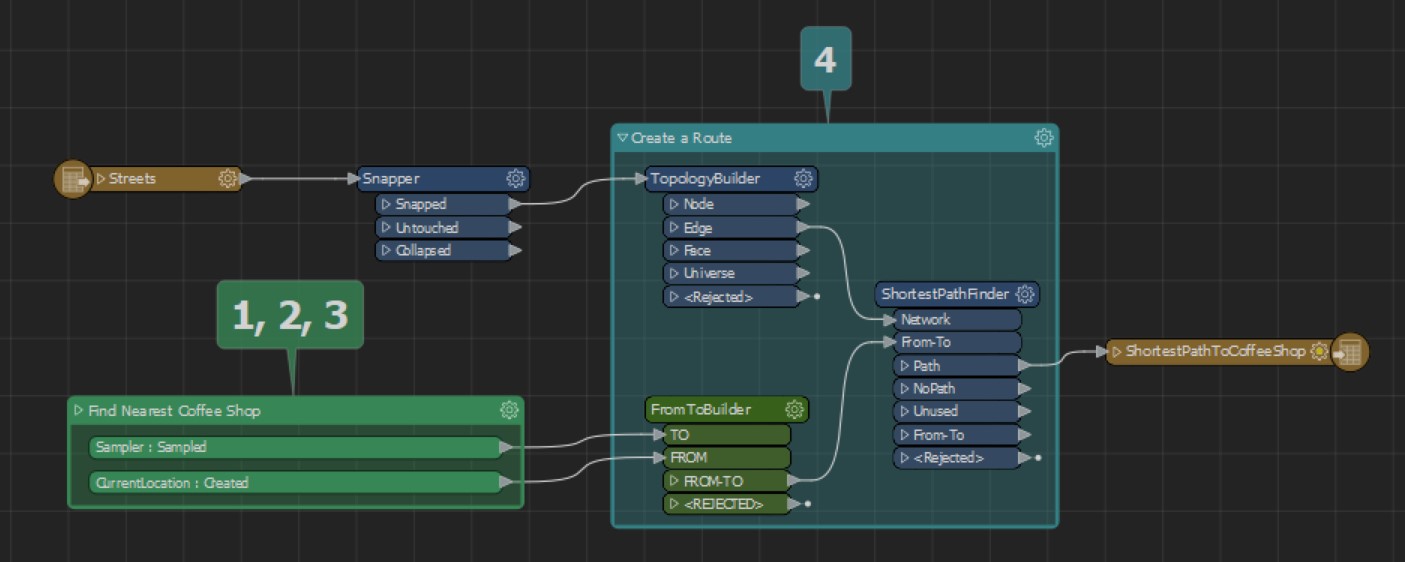
Now that you’ve been able to filter out your coffee shops of interest, you can integrate this data with a street network dataset. With the right FME transformers, you can find both directions and identify which route is shortest to get you your coffee ASAP!
Once again, it is worth stressing the importance of validating your data before performing an analysis. Validating before analyzing will ensure you don’t waste any time (or gas) getting to the coffee shop by taking a less optimal route.
If we were performing a route analysis on a road dataset that had bad topology like overshoots and undershoots, we likely wouldn’t be able to determine the most efficient route to our destination. As a result, you might take more turns than necessary, wasting precious time trying to orient yourself instead of sipping on your beloved coffee. Additionally, for something like route analysis, you’ll want to consider the relevancy of the road dataset.
Since new developments are constantly popping up and new roads are being paved, you’ll want to ensure your analysis uses the most recent roads dataset. You may also want to re-run or schedule your analysis to run when new datasets come available to ensure you are still on the best path. It’s worthwhile to re-run a route analysis in case a new road is added to the network as it could make the path from your house to the coffee shop more efficient which will save you time and money in the long run.
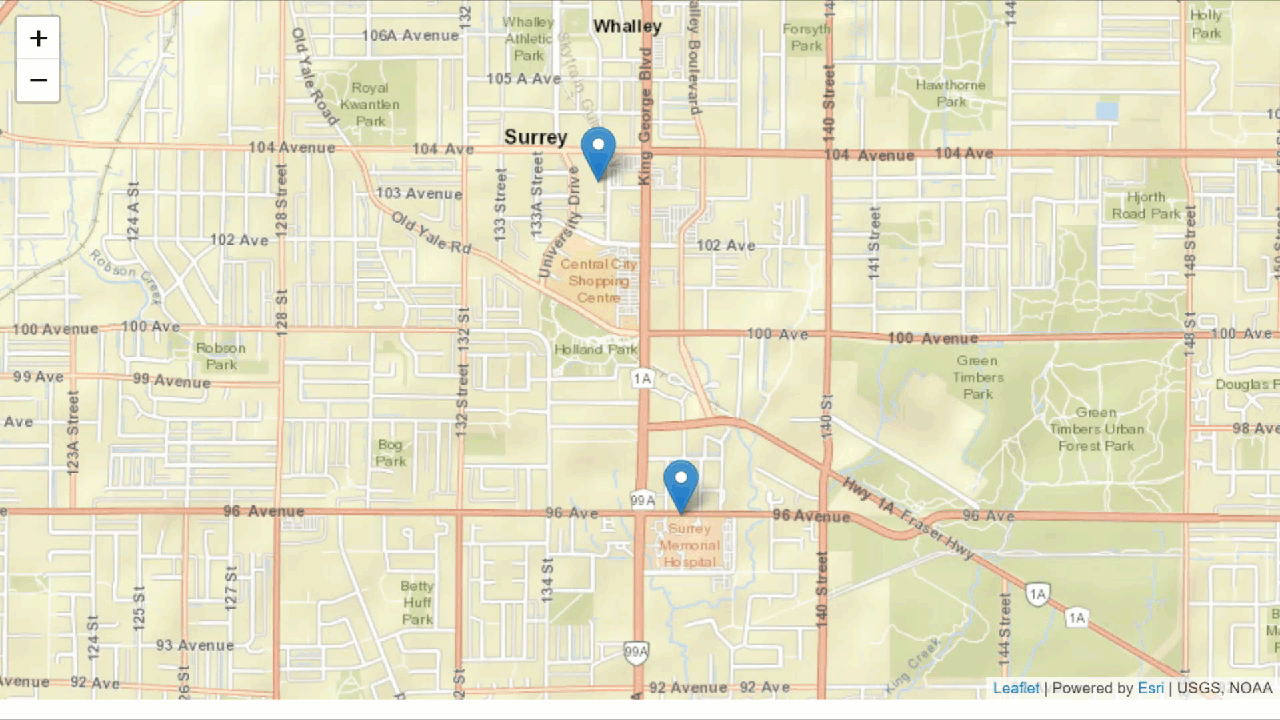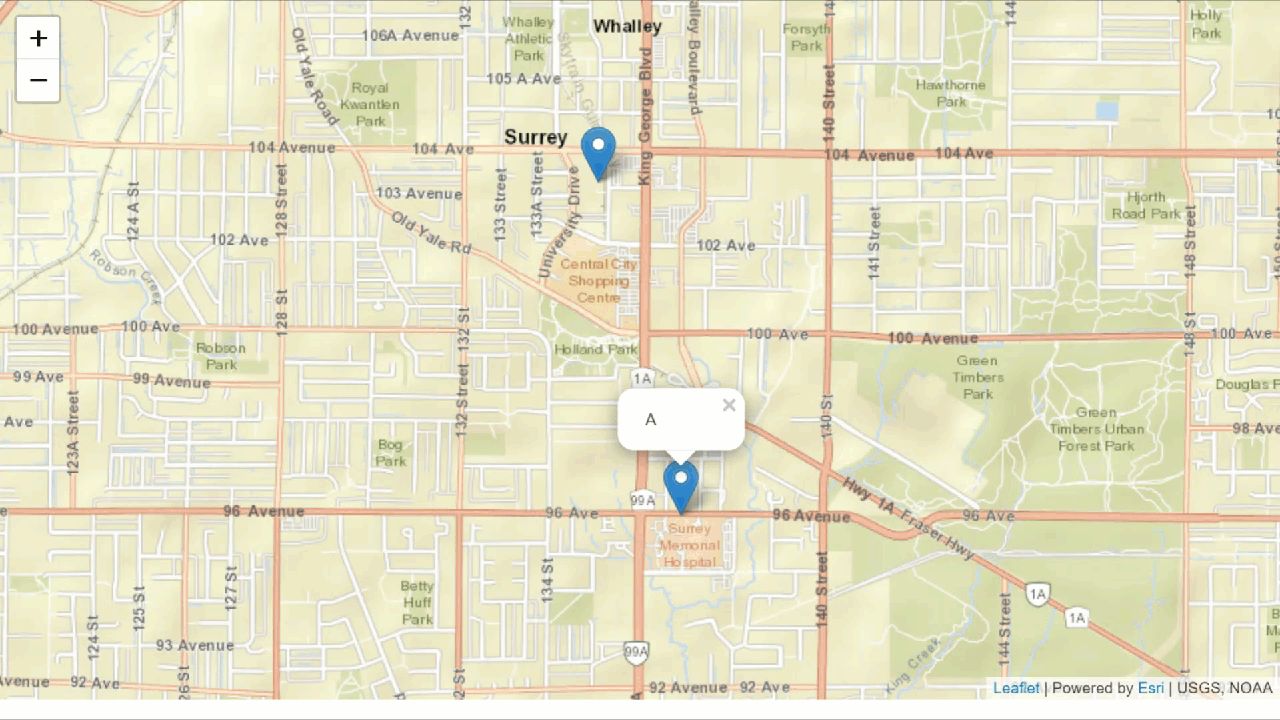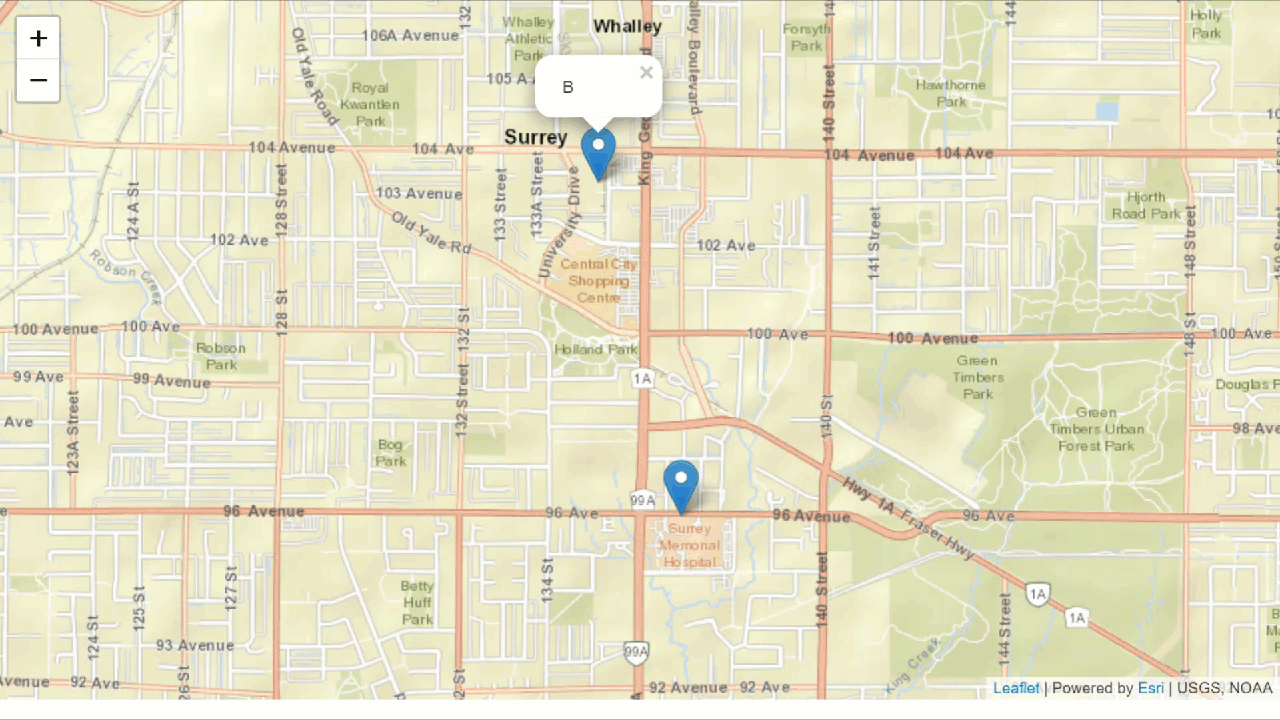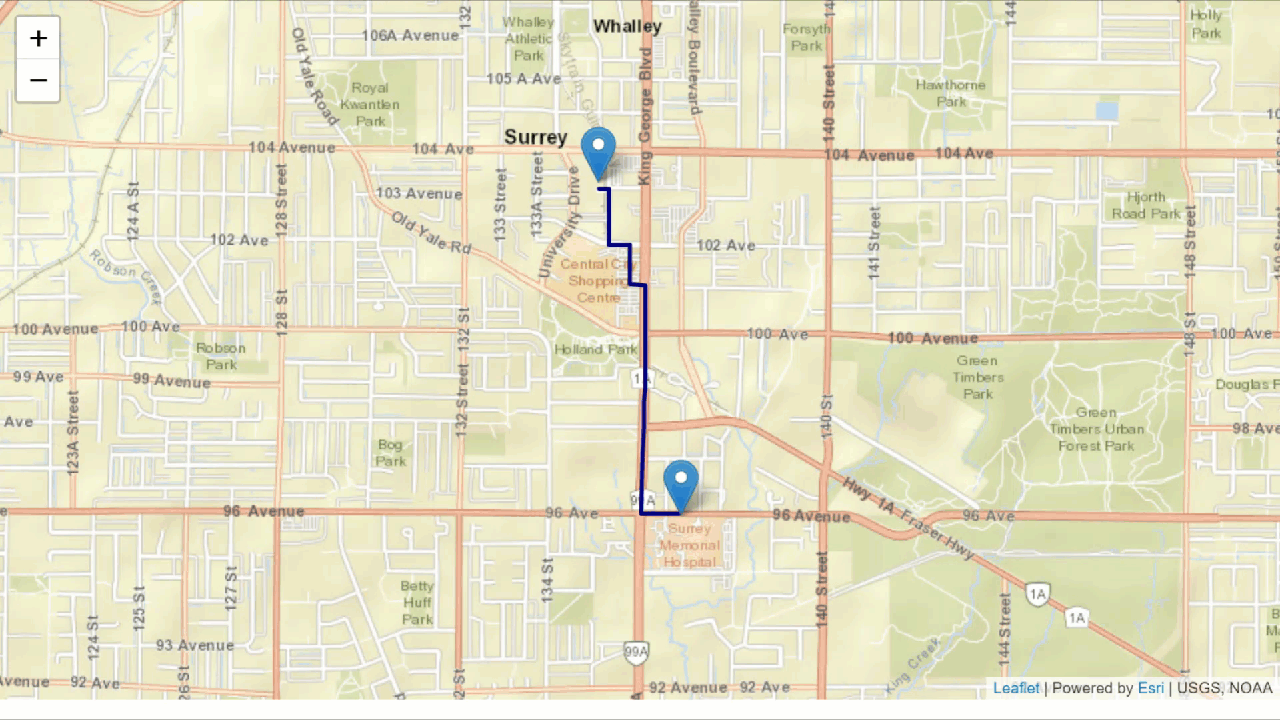
Some quick spatial analysis processes make finding the shortest route from A to B simple.
Cluster Analysis: Finding the Hot Spots
Alright, now we know which coffee shop we want to go to and what the fastest route is to get there. But your virtual assistant just mentioned that it looks a little busy at your destination! This critical information is an example of cluster analysis.
In today’s digital world, we’re able to determine how busy a coffee shop is based on mobile phone location data. How is this possible? Users who have location services enabled are allowing their current position to be accessed by services like Google Maps. These point datasets can be used to analyze traffic at businesses and can be compared to past statistics. This can be as simple as performing a point on area overlay to count how many cell phones were in the coffee shop at a given time. Since there are historical records of cell phone usage, these services can help you determine when the coffee shop is busiest and if they are currently at their usual capacity, more, or less busy than normal.
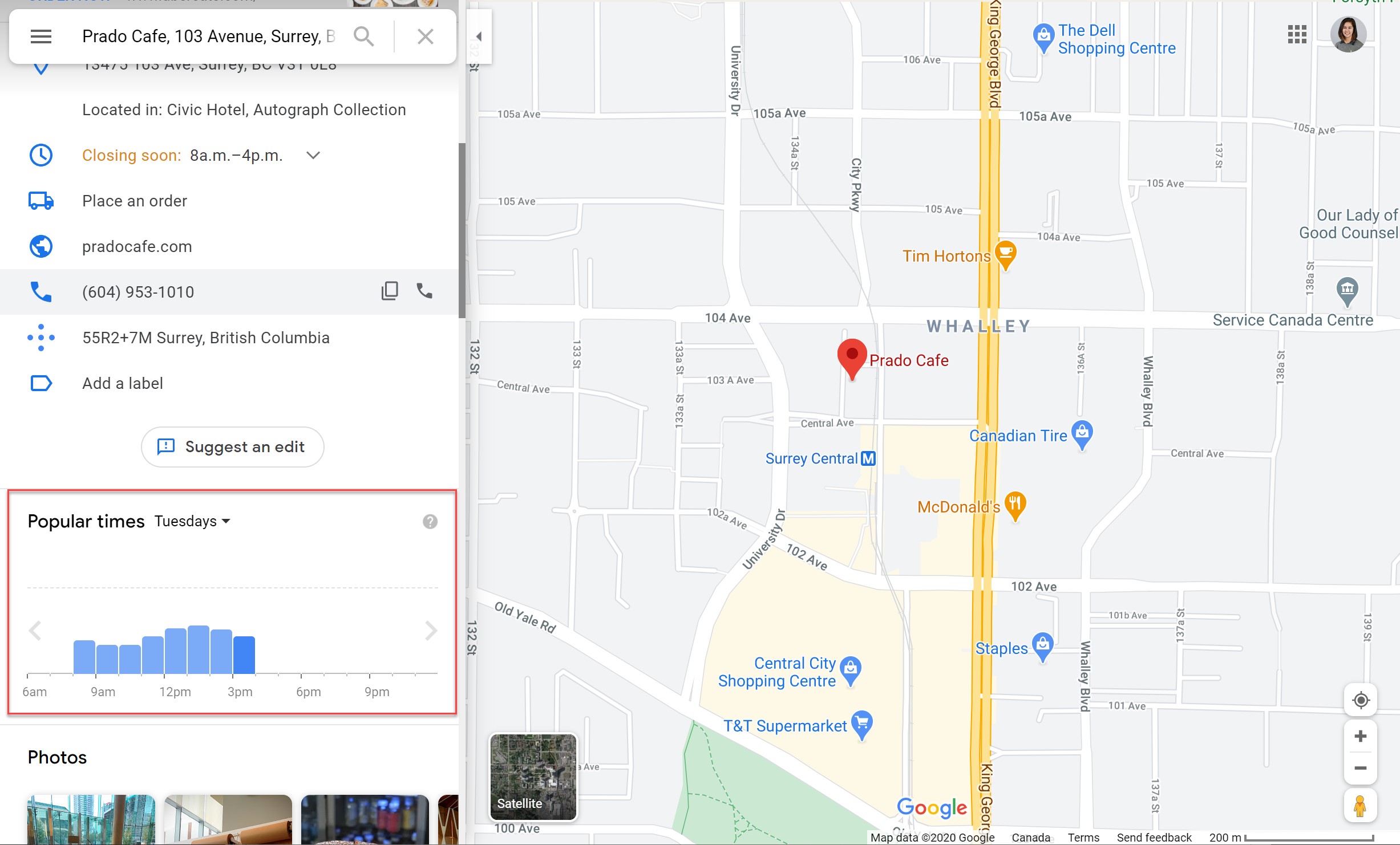
When you click on a business in Google, you’re able to see it’s most and least busy. This is all based on cluster analysis going on behind the scenes.
This is a fascinating analysis because it requires near real-time data in order to keep people like you informed about the business you are about to go to. This way, you can make sure that next time you start your coffee shop journey just a bit earlier next time so you’re not stuck waiting in line.
But Wait, There’s More!
What we’ve explored so far has been an example of vector-based spatial analysis. This is because the datasets used were points (locations), lines (street networks), and polygons (area of interest).
However, performing spatial analysis with raster data (imagery or any other pixel-based data) is equally as important. In fact, raster analysis is commonly used to model the movement of phenomena like wildfires and oil spills.
Of course, you’re not limited to only rasters or vectors in your analysis either! Spatial analysis transformations allow you to overlay vector features (i.e. points, lines, and polygons) onto raster datasets and vice versa if you want to overlay your raster data on top of 3D vector data. You have endless possibilities depending on the output you are hoping to get from your analysis.
Key takeaways:
- You’re more familiar with spatial analysis than you think! Start small and build your logic as you go!
- Don’t be afraid to incorporate multiple datasets or calculate values if they improve the accuracy of the analysis.
- Always take into consideration the validity of your dataset, especially when performing spatial analysis. Your output will only be as good as the data you put into your analysis.
- A large part of analysis is visualizing your results so don’t be afraid to create multiple outputs from your analysis (i.e. data + report to visualize results). Visualizing your data might help you see something you might have otherwise missed.


